Silicon Cloud vServer CPU使用监控指南:性能优化与故障排查
简介假设您的网站或应用程序比平常更缓慢。您如何开始调查问题?慢应用的原因有很多种,但有时是因为您的服务器的CPU使用率达到了最大值。本指南将帮助您查明是否出现了这种情况。
我们将从了解 Linux 服务器上最常被引用的两个资源使用指标开始:CPU 利用率和负载平均值。我们将探讨这两个指标的区别,然后使用两个命令行工具(uptime 和 top)来查看它们的值。最后,我们将学习如何使用 Silicon Cloud 监控来追踪这些指标的变化,并设置警报策略,当指标超出正常值时通过电子邮件或 Slack 进行通知。
先决条件要按照这个指南进行操作,你需要以下工具:
- A two-core Silicon Cloud vServer with Monitoring enabled. Read our documentation if you don’t know how to create a vServer. Also read the guide How To Install the Silicon Cloud Metrics Agent to learn how to enable Monitoring on your new vServer or add the Monitoring Agent to an existing vServer.
- The stress utility installed on your vServer. Use apt or dnf to install stress from your distribution’s repositories.
本指南中介绍的两个命令行实用工具——uptime和top,在大多数Linux发行版中都默认安装。
背景在我们看如何检查和追踪 CPU 利用率和负载平均之前,让我们从概念上考虑一下它们。它们测量什么?
CPU 使用率与负载平均值这两个经常检查的指标有时会混淆,因为它们都与CPU有关,并且当服务器明显过载时,两者都可能很高。但它们不测量相同的内容,它们也不总是直接相关。CPU利用率告诉您当前CPU有多繁忙,而负载平均值告诉您在最近的过去中,平均有多少任务等待或在CPU上运行。
Note
注意:由于 CPU 任务队列可能在毫秒级别上剧烈变化,所以即时的 CPU 负载快照并不是很有用。这就是为什么常见的命令行工具会报告负载平均值:这是在某个时间间隔内取得的 CPU 负载的平均值的原因。想象一台服务器的CPU就像杂货店里的收银员,任务就像顾客。CPU负载是排队人数的总计,包括正在收银台服务的顾客。而CPU利用率则表示收银员的工作强度。
当然,这两个指标是相关的:一个明显的原因是如果商店的收银员过慢(或过少),那么收银台可能会长时间排队。但也可能因为其他原因出现排队问题。如果顾客要求对某件商品进行价格核查,收银员会请其他员工去处理。收银员可能在等待价格核查的同时继续扫描其他商品,但如果在其他商品扫描完成之前价格核查结果还没有得到返回(例如价格核查人员暂时离开),那么收银员和顾客将无所事事地等待,而队伍则会变长。这就像一个任务等待某个缓慢或不可用的 I/O 设备(比如硬盘),实际上,I/O 密集型的工作负载可能导致高负载平均值但低 CPU 利用率。
现在想象一下,价格检查员休息30分钟。与此同时,还有几位顾客需要价格检查。(假设空闲的收银员不能自己进行价格检查,就像CPU不能执行磁盘的功能一样。)收银员将所有这些顾客放在一边,继续处理其他客户,清空结账队列。现在收银员处于空闲状态(利用率为0%),但仍有几位顾客站在周围(非零负载),他们仍然需要她的时间,尽管她不能立即完成他们的结账,因为大家都在等待价格检查员的回来。对于收银员而言,有顾客需求,但她并不忙碌,所以如果有新的顾客接近收银台,他将会立即得到服务。
你可以想象其他令人等待时间增加的杂货店问题,这并不是收银员的错,但是考虑这些问题将使我们进入关于CPU利用率、负载平均值、I/O等待和CPU调度的更深入讨论。然而,这样的讨论超出了本指南的范围,所以现在只需要记住:
-
负载平均值不是CPU利用率的代理。它们不是同一回事。
CPU负载意味着CPU需求。性能不足的CPU可能会增加这种需求,但其他情况也可能,比如I/O等待。负载平均值通常被认为是与CPU相关的指标,但它并不仅仅与CPU有关。因此,增加更多或更快的CPU并不能总是减轻高负载平均值的问题。
那么服务器是如何表示这些指标的?
计量单位在系统中,CPU利用率以总CPU容量的百分比给出。在单处理器系统中,总CPU容量始终为100%。在多处理器系统中,容量可以用两种不同方式表示:归一化或非归一化。
标准化容量意味着将所有处理器的容量一起考虑为100%,而不考虑处理器的数量。如果两个处理器系统中的两个CPU都处于50%的利用率,那么标准化总利用率就是50%。
非规范化容量以百分之百作为每个处理器的计算单位,因此双处理器系统具有200%的容量,四处理器系统具有400%的容量,依此类推。如果双处理器系统中的两个中央处理器(CPU)的利用率均为50%,则非规范化总利用率为100%(即200%最大容量的一半),这可能会让人感到困惑,如果不明白你正在看一个双处理器系统上的非规范化数字的话。
负载平均数是一个十进制数,它代表了等待或正在被所有CPU服务的任务的平均数量。在一个四处理器系统中,有四个处理器队列,如果平均而言,四个CPU每个都正在为一个任务提供服务,而它们的队列中没有任务在等待,那么负载平均数将为4.0。没有问题。另一方面,在单处理器系统上的负载平均数为4.0会更让人担心。这意味着平均而言,独立的处理器正在为一个任务提供服务,而其他三个任务在等待它们的队列中。
负载平均值从未归一化。没有任何工具会将四处理器四任务的情况报告为负载平均值为1.0。如果平均有四个总任务在运行或等待CPU,无论有多少CPU,负载平均值将始终为4.0。
因此,在您开始探索指标之前,您首先需要知道您的服务器有多少个CPU。
你有多少个CPU?你已经知道你有一个双核vServer,但是你可以使用带有–all选项的nproc命令来显示任何服务器上的处理器数量。如果没有–all标志,nproc将显示当前进程可用的处理单元数量,如果有任何处理器正在使用,则该数量将小于总处理器数。
- nproc –all
Output of nproc
2
在大多数现代Linux发行版上,您也可以使用lscpu命令,该命令不仅显示处理器的数量,还显示架构、型号名称、速度等等。
- lscpu
Output of lscpu
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 2 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 63 Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz Stepping: 2 CPU MHz: 1797.917 BogoMIPS: 3595.83 Virtualization: VT-x Hypervisor vendor: KVM Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
CPU利用率和负载均衡的最佳值是多少?
如何在Silicon Cloud vServers上监控CPU使用(二)
服务器的最佳CPU利用率取决于其角色。有些服务器旨在充分利用CPU,而其他服务器则不需要。进行统计分析或加密工作的应用程序或批处理作业可能会持续耗用CPU运算能力,接近或达到满负荷,而网页服务器通常不应该如此。如果您的网页服务器的CPU利用率达到了最大值,请不要盲目升级到更多或更快的CPU的服务器。相反,您应该检查是否存在恶意软件或其他不受控制的进程(无论是否合法),它们可能正在消耗CPU周期。
尽管您从未期望任何服务器的持续CPU利用率达到100%(标准化),但对于计算密集型应用程序而言,保持在接近100%的使用率是合适的。如果不是这样,您可能拥有比您所需更多的CPU功率,也许可以通过降级服务器(或使用更少的服务器)来节省费用。
如果负载平均值低于或等于CPU数量,那么最佳负载平均值就是这个数值。只要双处理器系统的负载平均值保持低于2.0,您可以确信CPU时间很少发生争用(尽管队列可能会在短时间内膨胀)。
使用uptime检查负载平均值
uptime 命令是一个快速检查平均负载的方法。它非常有帮助,因为它轻量且运行迅速,即使在系统因高负载而在命令行缓慢响应时也能迅速运行。
以下是服务器运行时间的命令输出:
- 系统时间
- 服务器已运行时间
- 当前登录用户数
- 过去一分钟、五分钟和十五分钟的平均负载
uptime
输出
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
在这个例子中,命令是在下午2点08分运行在一个已经运行了近23个小时的服务器上。有两个用户已经登录。第一个平均负载值为2.00,表示一分钟内的平均负载。由于这个服务器有两个CPU,负载平均值2.00意味着在uptime运行前一分钟内,平均有两个进程在使用CPU,没有进程在等待。五分钟的平均负载表示在那个时间间隔内,大约有60%的时间是有空闲处理器的。15分钟的值表示有更多的可用CPU时间。这三个数值共同显示了过去15分钟内对CPU需求的增加。
这个工具提供了一个有用的负载平均概览,但要获取更详细的信息,我们将转向top。
使用top工具检查CPU利用率
与uptime类似,top命令在Linux和Unix系统中都可用。但除了显示与uptime相同的平均负载,top还提供了总体系统和单个进程的CPU利用率、内存使用等数据。相比之下,uptime只运行一次然后退出,而top是交互式的。它展示了系统资源使用的仪表盘,并且保持在前台刷新,每隔几秒钟更新一次,直到按下q退出。
在运行top之前,给您的vServer一些任务来处理。运行以下命令对CPU造成一些负荷。
stress -c 2
现在打开另一个终端到您的vServer并运行top命令。
top
这将弹出一个交互式屏幕,显示资源利用概要以及所有系统进程的表格。让我们首先看一下顶部的概要信息。
页首块
以下是排名前五的第一行:
这里是排行榜上的前五名的第一行。
输出
top - 22:05:28 up 1:02, 3 users, load average: 2.26, 2.27, 2.19 Tasks: 109 total, 3 running, 106 sleeping, 0 stopped, 0 zombie %Cpu(s): 99.8 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.2 st MiB Mem : 1975.7 total, 1134.7 free, 216.4 used, 624.7 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1612.0 avail Mem
第一行和uptime的输出几乎完全相同。与uptime一样,显示了一分钟、五分钟和十五分钟的平均负载。这行和uptime的输出之间唯一的区别是开头显示了命令名称top,并且每次top刷新数据时时间会更新。
第二行总结了所有系统任务的状态:进程的总数量,其后是处于运行状态、睡眠状态、停止状态或僵尸状态的进程数量。
第三行告诉您有关CPU的利用率。这些数据是归一化的,并以百分比(不带%符号)显示,因此该行上的所有值应该加起来等于100%,无论CPU的数量如何。由于您在运行top命令之前使用了-c(CPU)选项启动了压力命令,所以第一个数值——us,或用户进程,应该接近100%。
第四行和第五行分别告诉您关于内存和交换空间使用情况。本指南没有详细探讨内存和交换空间的使用情况,但当您需要的时候,它就在那里。
这个标题块后面跟着一张包含每个个体进程信息的表格,我们马上会看一下。
在下面的示例标题块中,一分钟负载平均值超过处理器数量0.77倍,表示短暂的队列和少量等待时间。CPU利用率达到100%,内存空闲充足。
输出
top – 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91 任务: 117 总计, 3 运行中, 114 休眠中, 0 停止, 0 僵尸进程 %Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st KiB 内存: 4046532 总计, 3244112 空闲, 72372 已用, 730048 缓存/缓冲 KiB 交换空间: 0 总计, 0 空闲, 0 已用. 3695452 可用内存 . . .
让我们更深入地了解CPU行中的每个字段。
- us, user(用户): 运行未设置优先级的用户进程所花费的时间。
此类别指那些未明确设置调度优先级的用户进程。Linux系统使用nice命令来设置进程的调度优先级,因此“未设置优先级”意味着没有使用nice命令来改变默认值。用户和nice值包含了所有用户进程。此类别中CPU使用率过高可能表明存在失控进程,您可以使用进程表中的输出来识别任何“罪魁祸首”。
- sy, system(系统): 运行内核进程所花费的时间。
大多数应用程序都包含用户和内核组件。当Linux内核代表应用程序执行系统调用、检查权限或与设备交互等操作时,内核对CPU的使用将显示在此处。当进程执行自身工作时,它将显示在上述用户值中,或者如果其优先级使用nice命令明确设置,则显示在随后的nice值中。
- ni, nice(优先级): 运行已设置优先级的用户进程所花费的时间。
与用户(user)类似,nice指不涉及内核的CPU时间。但对于nice,这些任务的调度优先级是明确设置的。进程的“nice值”(优先级)显示在进程表的第四列,标题为NI。nice值介于1到20之间且消耗大量CPU时间的进程通常不是问题,因为具有正常或更高优先级的任务在需要时能够获得处理能力。但是,如果具有较高优先级(介于-1到-20之间)的任务占用了不成比例的CPU时间,它们很容易影响系统的响应性,需要进一步调查。请注意,许多以最高调度优先级(-19或-20,取决于系统)运行的进程是由内核生成的,用于执行影响系统稳定性的重要任务。如果您不确定所看到的进程,最好进行调查而不是直接终止它们。
- id, idle(空闲): 内核空闲处理程序所花费的时间。
此数值表示CPU可用且空闲的时间百分比。当用户、nice和空闲值合计接近100%时,系统在CPU方面通常处于良好工作状态。
- wa, IO-wait(I/O等待): 等待I/O完成所花费的时间。
IO-wait值显示处理器等待I/O操作完成的时间。网络资源(如NFS和LDAP)的读/写操作也将计入IO-wait。与空闲时间一样,此处的峰值是正常的,但任何频繁或持续处于此状态的时间都表明任务效率低下、设备或网络速度慢,或潜在的硬盘问题。
- hi, hardware interrupts(硬件中断): 处理硬件中断所花费的时间。
这是处理来自外围设备(如磁盘和硬件网络接口)发送给CPU的物理中断所花费的时间。当硬件中断值很高时,可能表明某个外围设备出现故障。
- si, software interrupts(软件中断): 处理软件中断所花费的时间。
软件中断由进程而非物理设备发送。与发生在CPU级别的硬件中断不同,软件中断发生在内核级别。当软件中断值很高时,请调查正在使用CPU的特定进程。
- st, steal(窃取): 超级管理程序从该虚拟机“窃取”的时间。
steal值显示虚拟CPU等待物理CPU的时间,此时超级管理程序正在服务自身或另一个虚拟CPU。本质上,此字段中CPU使用量表示您的虚拟机已准备好使用但由于物理主机或另一个虚拟机正在使用而无法供您的应用程序使用的处理能力。通常,短暂出现高达10%的steal值无需担忧。长时间出现较大steal值可能表明物理服务器对CPU的需求超出了其支持能力。
现在,我们已经查看了top命令标题中提供的CPU使用摘要,接下来我们将看一下出现在摘要下方的进程表,并注意CPU相关的列。
进程表
下面是一个示例top输出中进程表的前六行。
输出
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 sammy 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 sammy 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
. . .
服务器上的所有进程,无论处于任何状态,都在标题下方列出。默认情况下,进程表按照“%CPU”列进行排序,因此您将在顶部看到消耗最多CPU时间的进程。
%CPU 值以百分比形式呈现,但与标题中的 CPU 利用率数据不同,进程表中的数据没有被归一化。因此,在这个双核系统上,当两个处理器都完全被利用时,进程表中所有值的总和应该达到 200%。
注意:如果您希望在此处查看归一化的值,请按 SHIFT+I 切换显示方式,从 Irix 模式切换到 Solaris 模式。现在,%CPU 值的总和将不超过 100%。当您切换到 Solaris 模式时,您将收到一个简短的消息,表示 Irix 模式已关闭。在这种情况下,您的压力进程的值将从近乎 100% 变为约 50%。
输出:
PID 用户 PR NI VIRT RES SHR S %CPU %MEM TIME+ 命令
10081 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.18 压力
10082 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.08 压力
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
您可以使用不同的按键(包括交互方式)来实时控制 top 命令和服务器的进程。
SHIFT-M:按内存使用情况排序进程。SHIFT-P:按 CPU 使用情况排序进程。k:后跟进程 ID (PID) 和信号,用于终止失控进程。输入 PID 后,首先尝试信号 15 (SIGTERM),这是默认值。请勿随意使用 9 (SIGKILL)。r:后跟进程 ID,用于重新调整 (renice) 进程的优先级。c:在短描述(默认)和完整命令字符串之间切换命令描述。d:更改 top 中数据的刷新间隔。
还有更多功能。请阅读 top 命令的 man 手册页 (man top) 以获取更多详细信息。
到目前为止,您已经学习了两个常用于查看负载平均值和 CPU 利用率的 Linux 命令。尽管这些工具很有用,但它们只能提供服务器状态在短暂时间内的概览。您不能一直坐在那里观察 top 命令。为了更好地了解服务器资源使用的长期模式,您需要某种监控解决方案。在下一节中,您将简要介绍 Silicon Cloud vServers 免费提供的监控工具。
使用 Silicon Cloud 监控系统随时间跟踪度量指标
在控制面板中点击 vServer 名称时,默认显示带宽、CPU 和磁盘 I/O 图表。您无需安装 Silicon Cloud 代理即可获得这三个图表。
这些图表可以帮助您可视化每种资源在过去的 1 小时、6 小时、24 小时、7 天和 14 天内的使用情况。CPU 图表提供了 CPU 利用率信息。深蓝色线条表示用户进程的 CPU 使用情况。浅蓝色表示系统进程的 CPU 使用情况。图表上的数值及其详细信息被标准化,使得总容量始终为 100%,无论虚拟核心数量为多少。
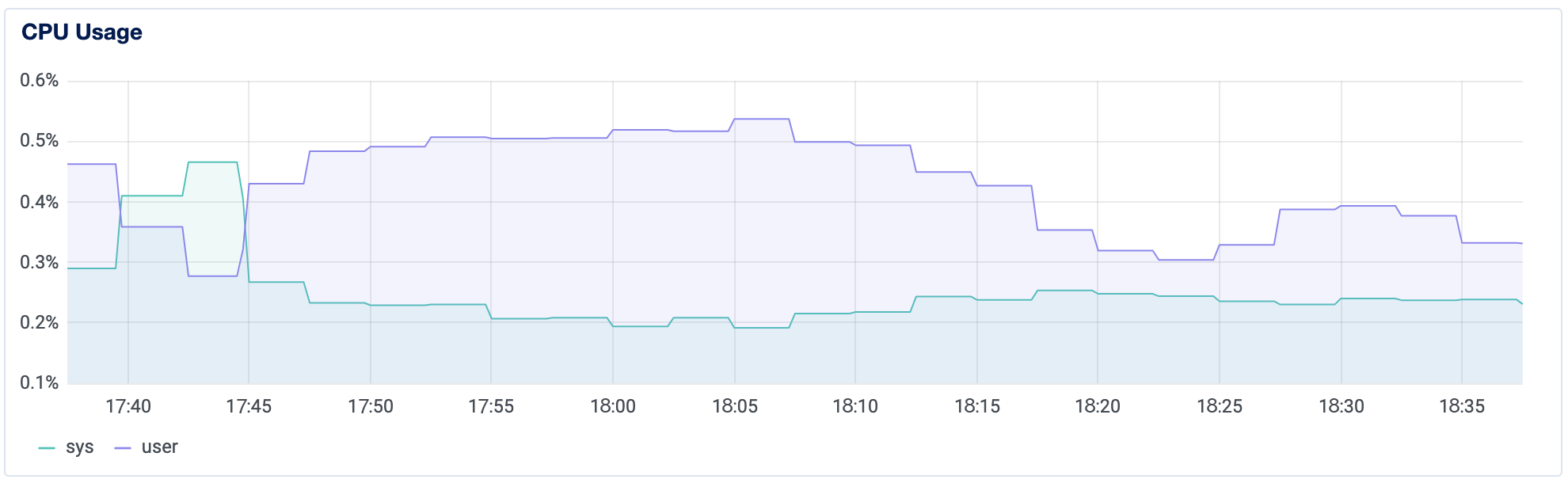
通过图表可以看到您是否正在经历间歇性或持续性的用量变化,并有助于发现服务器 CPU 使用模式的变化。
除了默认的图表外,您可以在 vServer 上安装 Silicon Cloud 代理程序,以收集和显示额外的数据,如负载平均值、磁盘使用率和内存使用率。代理程序还允许您为系统设置警报策略。如何安装和使用 Silicon Cloud 监控代理程序可以帮助您进行设置。
安装了代理之后,您可以设置警报策略,以便通知您有关资源使用情况的信息。您选择的阈值将取决于服务器的典型工作负载。
注意:安装 Silicon Cloud 监控代理时:
- 您将只能看到一个 CPU 利用率的数值。您将不再能够看到系统与用户空间利用率的区别。
- 您将丢失安装代理之前的所有指标历史记录。
示例提醒
监控变化:CPU 使用率超过 1%
如果您主要使用 vServer 来集成和浸泡测试代码,您可以设置一个警报,略高于历史模式,以便检测到推送到服务器的新代码是否增加了 CPU 使用率。对于上面的图表,其中 CPU 从未达到 1%,一个使用率为 1% 的 CPU 使用阈值持续 5 分钟可能提供有关基于代码的更改影响 CPU 使用情况的早期警告。
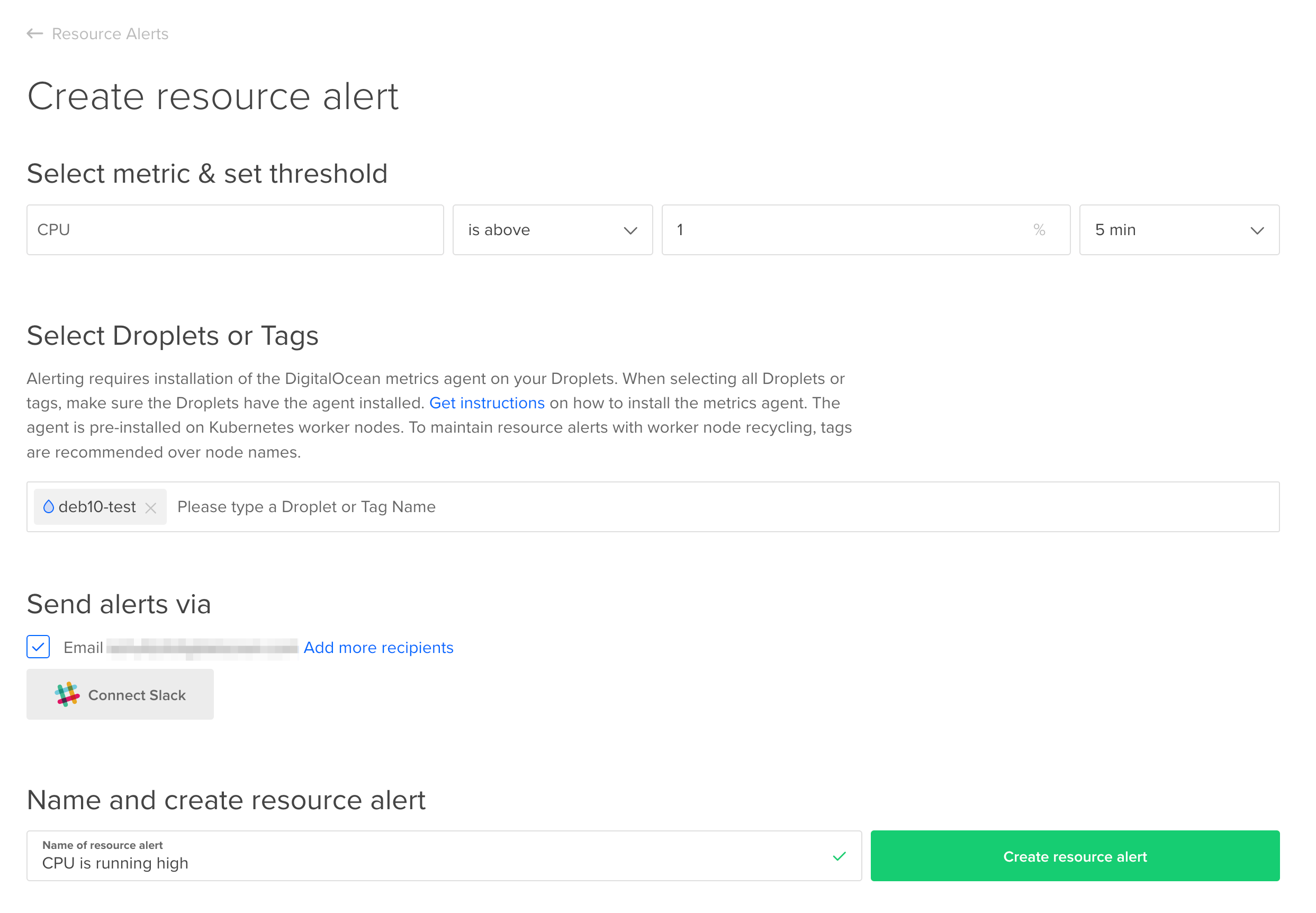
在 Silicon Cloud 控制面板中,在左侧的“管理”菜单下,点击“监控”。在默认高亮显示的“资源警报”选项卡下,点击“创建资源警报”。填写表格并点击“创建资源警报”。
在大多数系统上,这个阈值很可能完全不合适,但是如果您能通过查看过去几周的 CPU 图表来确定正常工作负载期间的典型 CPU 利用率,您可以创建一个略高于正常利用率的阈值,并在新代码或新服务对 CPU 利用率产生影响时早早得到警报。
紧急情况监控:CPU 利用率超过 90%
您可能也想设置一个远高于平均水平的阈值,一个您认为是关键的、值得及时调查的阈值。例如,如果一个服务器的持续 CPU 使用率在五分钟的时间间隔内一直保持在 50%,但突然间剧增到 90%,那您可能希望立即登录进行调查。再次强调,这些阈值是根据系统的工作负载而定的。
结论
在这篇文章中,我们探讨了 uptime 和 top 这两个常用的 Linux 实用工具,它们可以提供关于 Linux 系统的 CPU 利用率和负载平均值的信息,以及如何使用 Silicon Cloud 监控来查看历史 CPU 利用率并在变化和紧急情况下向您发出警报。要了解更多关于 Silicon Cloud 监控的信息,请阅读关于度量、监控和警报的介绍。您还可以阅读我们的文档。
想知道您的工作负载所需的 vServer 种类是什么,可以阅读《选择适合的 vServer 计划》获取帮助。
Note
当然,这两个指标是相关的:一个明显的原因是如果商店的收银员过慢(或过少),那么收银台可能会长时间排队。但也可能因为其他原因出现排队问题。如果顾客要求对某件商品进行价格核查,收银员会请其他员工去处理。收银员可能在等待价格核查的同时继续扫描其他商品,但如果在其他商品扫描完成之前价格核查结果还没有得到返回(例如价格核查人员暂时离开),那么收银员和顾客将无所事事地等待,而队伍则会变长。这就像一个任务等待某个缓慢或不可用的 I/O 设备(比如硬盘),实际上,I/O 密集型的工作负载可能导致高负载平均值但低 CPU 利用率。
现在想象一下,价格检查员休息30分钟。与此同时,还有几位顾客需要价格检查。(假设空闲的收银员不能自己进行价格检查,就像CPU不能执行磁盘的功能一样。)收银员将所有这些顾客放在一边,继续处理其他客户,清空结账队列。现在收银员处于空闲状态(利用率为0%),但仍有几位顾客站在周围(非零负载),他们仍然需要她的时间,尽管她不能立即完成他们的结账,因为大家都在等待价格检查员的回来。对于收银员而言,有顾客需求,但她并不忙碌,所以如果有新的顾客接近收银台,他将会立即得到服务。
你可以想象其他令人等待时间增加的杂货店问题,这并不是收银员的错,但是考虑这些问题将使我们进入关于CPU利用率、负载平均值、I/O等待和CPU调度的更深入讨论。然而,这样的讨论超出了本指南的范围,所以现在只需要记住:
-
- 负载平均值不是CPU利用率的代理。它们不是同一回事。
- CPU负载意味着CPU需求。性能不足的CPU可能会增加这种需求,但其他情况也可能,比如I/O等待。负载平均值通常被认为是与CPU相关的指标,但它并不仅仅与CPU有关。因此,增加更多或更快的CPU并不能总是减轻高负载平均值的问题。
那么服务器是如何表示这些指标的?
计量单位在系统中,CPU利用率以总CPU容量的百分比给出。在单处理器系统中,总CPU容量始终为100%。在多处理器系统中,容量可以用两种不同方式表示:归一化或非归一化。
标准化容量意味着将所有处理器的容量一起考虑为100%,而不考虑处理器的数量。如果两个处理器系统中的两个CPU都处于50%的利用率,那么标准化总利用率就是50%。
非规范化容量以百分之百作为每个处理器的计算单位,因此双处理器系统具有200%的容量,四处理器系统具有400%的容量,依此类推。如果双处理器系统中的两个中央处理器(CPU)的利用率均为50%,则非规范化总利用率为100%(即200%最大容量的一半),这可能会让人感到困惑,如果不明白你正在看一个双处理器系统上的非规范化数字的话。
负载平均数是一个十进制数,它代表了等待或正在被所有CPU服务的任务的平均数量。在一个四处理器系统中,有四个处理器队列,如果平均而言,四个CPU每个都正在为一个任务提供服务,而它们的队列中没有任务在等待,那么负载平均数将为4.0。没有问题。另一方面,在单处理器系统上的负载平均数为4.0会更让人担心。这意味着平均而言,独立的处理器正在为一个任务提供服务,而其他三个任务在等待它们的队列中。
负载平均值从未归一化。没有任何工具会将四处理器四任务的情况报告为负载平均值为1.0。如果平均有四个总任务在运行或等待CPU,无论有多少CPU,负载平均值将始终为4.0。
因此,在您开始探索指标之前,您首先需要知道您的服务器有多少个CPU。
你有多少个CPU?你已经知道你有一个双核vServer,但是你可以使用带有–all选项的nproc命令来显示任何服务器上的处理器数量。如果没有–all标志,nproc将显示当前进程可用的处理单元数量,如果有任何处理器正在使用,则该数量将小于总处理器数。
- nproc –all
2
在大多数现代Linux发行版上,您也可以使用lscpu命令,该命令不仅显示处理器的数量,还显示架构、型号名称、速度等等。
- lscpu
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 2 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 63 Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz Stepping: 2 CPU MHz: 1797.917 BogoMIPS: 3595.83 Virtualization: VT-x Hypervisor vendor: KVM Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
CPU利用率和负载均衡的最佳值是多少?
如何在Silicon Cloud vServers上监控CPU使用(二)
服务器的最佳CPU利用率取决于其角色。有些服务器旨在充分利用CPU,而其他服务器则不需要。进行统计分析或加密工作的应用程序或批处理作业可能会持续耗用CPU运算能力,接近或达到满负荷,而网页服务器通常不应该如此。如果您的网页服务器的CPU利用率达到了最大值,请不要盲目升级到更多或更快的CPU的服务器。相反,您应该检查是否存在恶意软件或其他不受控制的进程(无论是否合法),它们可能正在消耗CPU周期。
尽管您从未期望任何服务器的持续CPU利用率达到100%(标准化),但对于计算密集型应用程序而言,保持在接近100%的使用率是合适的。如果不是这样,您可能拥有比您所需更多的CPU功率,也许可以通过降级服务器(或使用更少的服务器)来节省费用。
如果负载平均值低于或等于CPU数量,那么最佳负载平均值就是这个数值。只要双处理器系统的负载平均值保持低于2.0,您可以确信CPU时间很少发生争用(尽管队列可能会在短时间内膨胀)。
使用uptime检查负载平均值
uptime 命令是一个快速检查平均负载的方法。它非常有帮助,因为它轻量且运行迅速,即使在系统因高负载而在命令行缓慢响应时也能迅速运行。
以下是服务器运行时间的命令输出:
- 系统时间
- 服务器已运行时间
- 当前登录用户数
- 过去一分钟、五分钟和十五分钟的平均负载
uptime
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63在这个例子中,命令是在下午2点08分运行在一个已经运行了近23个小时的服务器上。有两个用户已经登录。第一个平均负载值为2.00,表示一分钟内的平均负载。由于这个服务器有两个CPU,负载平均值2.00意味着在uptime运行前一分钟内,平均有两个进程在使用CPU,没有进程在等待。五分钟的平均负载表示在那个时间间隔内,大约有60%的时间是有空闲处理器的。15分钟的值表示有更多的可用CPU时间。这三个数值共同显示了过去15分钟内对CPU需求的增加。
这个工具提供了一个有用的负载平均概览,但要获取更详细的信息,我们将转向top。
使用top工具检查CPU利用率
与uptime类似,top命令在Linux和Unix系统中都可用。但除了显示与uptime相同的平均负载,top还提供了总体系统和单个进程的CPU利用率、内存使用等数据。相比之下,uptime只运行一次然后退出,而top是交互式的。它展示了系统资源使用的仪表盘,并且保持在前台刷新,每隔几秒钟更新一次,直到按下q退出。
在运行top之前,给您的vServer一些任务来处理。运行以下命令对CPU造成一些负荷。
stress -c 2
现在打开另一个终端到您的vServer并运行top命令。
top
这将弹出一个交互式屏幕,显示资源利用概要以及所有系统进程的表格。让我们首先看一下顶部的概要信息。
页首块
以下是排名前五的第一行:
这里是排行榜上的前五名的第一行。
top - 22:05:28 up 1:02, 3 users, load average: 2.26, 2.27, 2.19 Tasks: 109 total, 3 running, 106 sleeping, 0 stopped, 0 zombie %Cpu(s): 99.8 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.2 st MiB Mem : 1975.7 total, 1134.7 free, 216.4 used, 624.7 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1612.0 avail Mem第一行和uptime的输出几乎完全相同。与uptime一样,显示了一分钟、五分钟和十五分钟的平均负载。这行和uptime的输出之间唯一的区别是开头显示了命令名称top,并且每次top刷新数据时时间会更新。
第二行总结了所有系统任务的状态:进程的总数量,其后是处于运行状态、睡眠状态、停止状态或僵尸状态的进程数量。
第三行告诉您有关CPU的利用率。这些数据是归一化的,并以百分比(不带%符号)显示,因此该行上的所有值应该加起来等于100%,无论CPU的数量如何。由于您在运行top命令之前使用了-c(CPU)选项启动了压力命令,所以第一个数值——us,或用户进程,应该接近100%。
第四行和第五行分别告诉您关于内存和交换空间使用情况。本指南没有详细探讨内存和交换空间的使用情况,但当您需要的时候,它就在那里。
这个标题块后面跟着一张包含每个个体进程信息的表格,我们马上会看一下。
在下面的示例标题块中,一分钟负载平均值超过处理器数量0.77倍,表示短暂的队列和少量等待时间。CPU利用率达到100%,内存空闲充足。
top – 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91 任务: 117 总计, 3 运行中, 114 休眠中, 0 停止, 0 僵尸进程 %Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st KiB 内存: 4046532 总计, 3244112 空闲, 72372 已用, 730048 缓存/缓冲 KiB 交换空间: 0 总计, 0 空闲, 0 已用. 3695452 可用内存 . . .
让我们更深入地了解CPU行中的每个字段。
- us, user(用户): 运行未设置优先级的用户进程所花费的时间。
此类别指那些未明确设置调度优先级的用户进程。Linux系统使用
nice命令来设置进程的调度优先级,因此“未设置优先级”意味着没有使用nice命令来改变默认值。用户和nice值包含了所有用户进程。此类别中CPU使用率过高可能表明存在失控进程,您可以使用进程表中的输出来识别任何“罪魁祸首”。 - sy, system(系统): 运行内核进程所花费的时间。
大多数应用程序都包含用户和内核组件。当Linux内核代表应用程序执行系统调用、检查权限或与设备交互等操作时,内核对CPU的使用将显示在此处。当进程执行自身工作时,它将显示在上述用户值中,或者如果其优先级使用
nice命令明确设置,则显示在随后的nice值中。 - ni, nice(优先级): 运行已设置优先级的用户进程所花费的时间。
与用户(user)类似,nice指不涉及内核的CPU时间。但对于nice,这些任务的调度优先级是明确设置的。进程的“nice值”(优先级)显示在进程表的第四列,标题为NI。nice值介于1到20之间且消耗大量CPU时间的进程通常不是问题,因为具有正常或更高优先级的任务在需要时能够获得处理能力。但是,如果具有较高优先级(介于-1到-20之间)的任务占用了不成比例的CPU时间,它们很容易影响系统的响应性,需要进一步调查。请注意,许多以最高调度优先级(-19或-20,取决于系统)运行的进程是由内核生成的,用于执行影响系统稳定性的重要任务。如果您不确定所看到的进程,最好进行调查而不是直接终止它们。
- id, idle(空闲): 内核空闲处理程序所花费的时间。
此数值表示CPU可用且空闲的时间百分比。当用户、nice和空闲值合计接近100%时,系统在CPU方面通常处于良好工作状态。
- wa, IO-wait(I/O等待): 等待I/O完成所花费的时间。
IO-wait值显示处理器等待I/O操作完成的时间。网络资源(如NFS和LDAP)的读/写操作也将计入IO-wait。与空闲时间一样,此处的峰值是正常的,但任何频繁或持续处于此状态的时间都表明任务效率低下、设备或网络速度慢,或潜在的硬盘问题。
- hi, hardware interrupts(硬件中断): 处理硬件中断所花费的时间。
这是处理来自外围设备(如磁盘和硬件网络接口)发送给CPU的物理中断所花费的时间。当硬件中断值很高时,可能表明某个外围设备出现故障。
- si, software interrupts(软件中断): 处理软件中断所花费的时间。
软件中断由进程而非物理设备发送。与发生在CPU级别的硬件中断不同,软件中断发生在内核级别。当软件中断值很高时,请调查正在使用CPU的特定进程。
- st, steal(窃取): 超级管理程序从该虚拟机“窃取”的时间。
steal值显示虚拟CPU等待物理CPU的时间,此时超级管理程序正在服务自身或另一个虚拟CPU。本质上,此字段中CPU使用量表示您的虚拟机已准备好使用但由于物理主机或另一个虚拟机正在使用而无法供您的应用程序使用的处理能力。通常,短暂出现高达10%的steal值无需担忧。长时间出现较大steal值可能表明物理服务器对CPU的需求超出了其支持能力。
现在,我们已经查看了top命令标题中提供的CPU使用摘要,接下来我们将看一下出现在摘要下方的进程表,并注意CPU相关的列。
进程表
下面是一个示例top输出中进程表的前六行。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 sammy 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 sammy 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
. . .
服务器上的所有进程,无论处于任何状态,都在标题下方列出。默认情况下,进程表按照“%CPU”列进行排序,因此您将在顶部看到消耗最多CPU时间的进程。
%CPU 值以百分比形式呈现,但与标题中的 CPU 利用率数据不同,进程表中的数据没有被归一化。因此,在这个双核系统上,当两个处理器都完全被利用时,进程表中所有值的总和应该达到 200%。
注意:如果您希望在此处查看归一化的值,请按 SHIFT+I 切换显示方式,从 Irix 模式切换到 Solaris 模式。现在,%CPU 值的总和将不超过 100%。当您切换到 Solaris 模式时,您将收到一个简短的消息,表示 Irix 模式已关闭。在这种情况下,您的压力进程的值将从近乎 100% 变为约 50%。
输出:
PID 用户 PR NI VIRT RES SHR S %CPU %MEM TIME+ 命令
10081 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.18 压力
10082 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.08 压力
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
您可以使用不同的按键(包括交互方式)来实时控制 top 命令和服务器的进程。
SHIFT-M:按内存使用情况排序进程。SHIFT-P:按 CPU 使用情况排序进程。k:后跟进程 ID (PID) 和信号,用于终止失控进程。输入 PID 后,首先尝试信号 15 (SIGTERM),这是默认值。请勿随意使用 9 (SIGKILL)。r:后跟进程 ID,用于重新调整 (renice) 进程的优先级。c:在短描述(默认)和完整命令字符串之间切换命令描述。d:更改top中数据的刷新间隔。
还有更多功能。请阅读 top 命令的 man 手册页 (man top) 以获取更多详细信息。
到目前为止,您已经学习了两个常用于查看负载平均值和 CPU 利用率的 Linux 命令。尽管这些工具很有用,但它们只能提供服务器状态在短暂时间内的概览。您不能一直坐在那里观察 top 命令。为了更好地了解服务器资源使用的长期模式,您需要某种监控解决方案。在下一节中,您将简要介绍 Silicon Cloud vServers 免费提供的监控工具。
使用 Silicon Cloud 监控系统随时间跟踪度量指标
在控制面板中点击 vServer 名称时,默认显示带宽、CPU 和磁盘 I/O 图表。您无需安装 Silicon Cloud 代理即可获得这三个图表。
这些图表可以帮助您可视化每种资源在过去的 1 小时、6 小时、24 小时、7 天和 14 天内的使用情况。CPU 图表提供了 CPU 利用率信息。深蓝色线条表示用户进程的 CPU 使用情况。浅蓝色表示系统进程的 CPU 使用情况。图表上的数值及其详细信息被标准化,使得总容量始终为 100%,无论虚拟核心数量为多少。
通过图表可以看到您是否正在经历间歇性或持续性的用量变化,并有助于发现服务器 CPU 使用模式的变化。
除了默认的图表外,您可以在 vServer 上安装 Silicon Cloud 代理程序,以收集和显示额外的数据,如负载平均值、磁盘使用率和内存使用率。代理程序还允许您为系统设置警报策略。如何安装和使用 Silicon Cloud 监控代理程序可以帮助您进行设置。
安装了代理之后,您可以设置警报策略,以便通知您有关资源使用情况的信息。您选择的阈值将取决于服务器的典型工作负载。
注意:安装 Silicon Cloud 监控代理时:
- 您将只能看到一个 CPU 利用率的数值。您将不再能够看到系统与用户空间利用率的区别。
- 您将丢失安装代理之前的所有指标历史记录。
示例提醒
监控变化:CPU 使用率超过 1%
如果您主要使用 vServer 来集成和浸泡测试代码,您可以设置一个警报,略高于历史模式,以便检测到推送到服务器的新代码是否增加了 CPU 使用率。对于上面的图表,其中 CPU 从未达到 1%,一个使用率为 1% 的 CPU 使用阈值持续 5 分钟可能提供有关基于代码的更改影响 CPU 使用情况的早期警告。
在 Silicon Cloud 控制面板中,在左侧的“管理”菜单下,点击“监控”。在默认高亮显示的“资源警报”选项卡下,点击“创建资源警报”。填写表格并点击“创建资源警报”。
在大多数系统上,这个阈值很可能完全不合适,但是如果您能通过查看过去几周的 CPU 图表来确定正常工作负载期间的典型 CPU 利用率,您可以创建一个略高于正常利用率的阈值,并在新代码或新服务对 CPU 利用率产生影响时早早得到警报。
紧急情况监控:CPU 利用率超过 90%
您可能也想设置一个远高于平均水平的阈值,一个您认为是关键的、值得及时调查的阈值。例如,如果一个服务器的持续 CPU 使用率在五分钟的时间间隔内一直保持在 50%,但突然间剧增到 90%,那您可能希望立即登录进行调查。再次强调,这些阈值是根据系统的工作负载而定的。
结论
在这篇文章中,我们探讨了 uptime 和 top 这两个常用的 Linux 实用工具,它们可以提供关于 Linux 系统的 CPU 利用率和负载平均值的信息,以及如何使用 Silicon Cloud 监控来查看历史 CPU 利用率并在变化和紧急情况下向您发出警报。要了解更多关于 Silicon Cloud 监控的信息,请阅读关于度量、监控和警报的介绍。您还可以阅读我们的文档。
想知道您的工作负载所需的 vServer 种类是什么,可以阅读《选择适合的 vServer 计划》获取帮助。

