R语言Quantile()函数完全指南:用法、实例与详解
这是文章《R中的分位数()函数 – 简要指南》的第1部分(共5部分)。
内容片段: 你可以使用R中的分位数()函数生成样本分位数。
大家好,今天我们将学习如何使用分位数()函数来找到数值的分位数。
分位数:通俗地讲,分位数就是将一个样本分为大小相等的组。基于这种特性,分位数也被称为百分位点。在分位数中,第25个百分位称为下四分位数,第50个百分位称为中位数,第75个百分位称为上四分位数。
让我们在下面的部分中看看如何在R中使用分位数()函数的工作原理。
分位数()函数的语法
在R中,分位数()函数的语法如下:
quantile(x, probs = , na.rm = FALSE)其中:
- x = 输入向量或数值
- probs = 0到1之间的概率值
- na.rm = 是否移除NA值,默认为FALSE
在R中实现分位数()函数的简单方法
希望你对分位数函数的定义和解释都了解清楚。现在,我们来看看在R中如何使用分位数函数,并通过一个简单的例子来返回输入数据的分位数。
# 创建一个包含一些值的向量,分位数函数将返回数据的百分位数
df <- c(12, 3, 4, 56, 78, 18, 46, 78, 100)
quantile(df)输出结果:
0% 25% 50% 75% 100%
3 12 46 78 100在上述样本中,你可以观察到分位数函数首先将输入值按升序排列,然后返回所需百分位的值。
请注意:分位数函数将数据均分为四等份,其中中位数作为中间值,低于中位数的部分称为下四分位,高于中位数的部分称为上四分位。
处理缺失值 - "NaN"
NaN值的存在在数据分析中很常见。在当今这个数据驱动的时代,我们经常会遇到这些NaN值,它们通常被称为缺失值。如果数据中存在这些缺失值,最终可能会导致输出结果为NaN或产生错误。
为了处理这些缺失值,我们可以使用na.rm参数。该参数会从数据中移除NA值,并返回有效的计算结果。
让我们来看一下它是如何工作的。
# 创建一个包含数值和NaN的向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df)
输出:
Error in quantile.default(df) :
missing values and NaN's not allowed if 'na.rm' is FALSE
如你所见,我们遇到了一个错误。如果你猜到这与NA值有关,那么你的判断是正确的。当数据中存在NA值时,大多数函数会返回NA值本身或显示上述错误信息。
现在,让我们使用na.rm参数来移除这些缺失值。
# 创建一个包含数值和NaN的向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
# 移除NA值并返回百分位数
quantile(df,na.rm = TRUE)
输出:
0% 25% 50% 75% 100%
3 12 46 78 100
在上面的示例中,你可以看到na.rm参数及其对输出结果的影响。该参数会移除NA值,以避免产生错误的输出结果。
quantile函数中的"probs"参数
正如您在这篇文章的第一部分所看到的,语法中的probs参数可能会让您好奇它的含义和工作原理。实际上,probs参数被传递给quantile函数,以获取特定的或自定义的百分位数。
看起来复杂吗?别担心,我会用简单的术语来解释。
每当您使用分位数函数时,它会返回标准的百分位数,如第25、第50和第75百分位数。但如果您需要第47百分位数或第88百分位数该怎么办呢?
这里有一个叫做"概率值"(probs)的参数,您可以通过它指定所需的百分位数来获取相应的值。
在查看示例之前,您应该了解一些关于probs参数的重要信息:
概率范围:概率参数的值应介于0和1之间。
以下示例可以说明上述要点:
# 创建数值向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
# 返回第22和第77百分位数
quantile(df,na.rm = T,probs = c(22,77))
结果:
Error in quantile.default(df, na.rm = T, probs = c(22, 77)) :
'probs' outside [0,1]
哦,这是一个错误!
您明白发生了什么吗?
问题在于,尽管我们在概率参数中指定了数值,但这些值违反了0-1的范围限制。概率参数必须包含介于0和1之间的值。
因此,我们需要将22和77转换为0.22和0.77。现在输入值介于0和1之间了,对吗?希望这样解释清楚了。
# 创建数值向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
# 返回输入值的第22和第77百分位数
quantile(df,na.rm = T,probs = c(0.22,0.77))
输出:
22% 77%
10.08 78.00
'未命名'函数及其使用
使用unname函数获取纯百分位数值
假设您希望代码只返回百分位数而不包含切割点。在这种情况下,您可以使用'unname'函数。
'unname'函数将删除标题或切分点(0%,25%,50%,75%,100%),并仅返回百分位数。
让我们看看它的运作方式吧!
#创建一个值向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#避免切分点并仅返回百分位数
unname(quantile(df,na.rm = T,probs = c(0.22,0.77)))
结果:
10.08 78.00
现在,您可以观察到由unname函数禁用或移除的切点,并仅返回百分位数。
使用'round'函数进行数值四舍五入
我们在过去的文章中详细讨论了R中的round函数。现在,我们将使用round函数来四舍五入这些数值。
我们来看看它是如何工作的!
#创建一个值向量
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#返回四舍五入后的值
unname(round(quantile(df,na.rm = T,probs = c(0.22,0.77))))
输出:
10 78
正如您所看到的,我们的输出值都被舍入到了零位小数。
在数据集中为多个组/列获取分位数
到目前为止,我们已经讨论了分位函数,它的用途和应用,以及它的参数和如何正确使用它们。
在本节中,我们将获取数据集中多个列的分位数。听起来有趣吗?跟着我来!
我将使用“mtcars”数据集来完成这项任务,并使用“dplyr”库进行操作。
#reads the data
data("mtcars")
#returns the top few rows of the data
head(mtcars)
#install required paclages
install.packages('dplyr')
library(dplyr)
#using tapply, we can apply the function to multiple groups
do.call("rbind",tapply(mtcars$mpg, mtcars$gear, quantile))
输出:按照以下方式用汉语进行翻译(只需要一种选择):
0% 25% 50% 75% 100%
3 10.4 14.5 15.5 18.400 21.5
4 17.8 21.0 22.8 28.075 33.9
5 15.0 15.8 19.7 26.000 30.4
在上述过程中,我们需要安装'dplyr'包,然后我们将使用tapply和rbind函数来获取mtcars数据集的多个列。
在上面的部分,我们选择了mtcars数据集中的多个列,例如'mpg'和'gear'列。像这样,我们可以计算数据集中多个组的分位数。
我们可以将百分位数进行可视化吗?我的答案是绝对肯定的!这个问题的最佳方案将是一个箱线图。让我拿鸢尾花数据集来尝试可视化箱线图,并展示百分位数。
我们出发吧!
data(iris)
head(iris)
 这是包含前6个值的鸢尾花数据集。
这是包含前6个值的鸢尾花数据集。
让我们通过名为“概要”的函数来探索数据。
summary(iris)
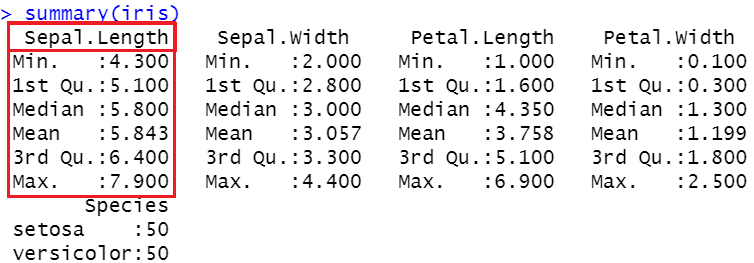 在上面的图像中,你可以看到均值、中位数、第一四分位数(25th百分位数)、第三四分位数(75th百分位数)以及最小值和最大值。让我们通过一个箱线图来绘制这些信息。
在上面的图像中,你可以看到均值、中位数、第一四分位数(25th百分位数)、第三四分位数(75th百分位数)以及最小值和最大值。让我们通过一个箱线图来绘制这些信息。
咱们一起做吧! zuò ba!)
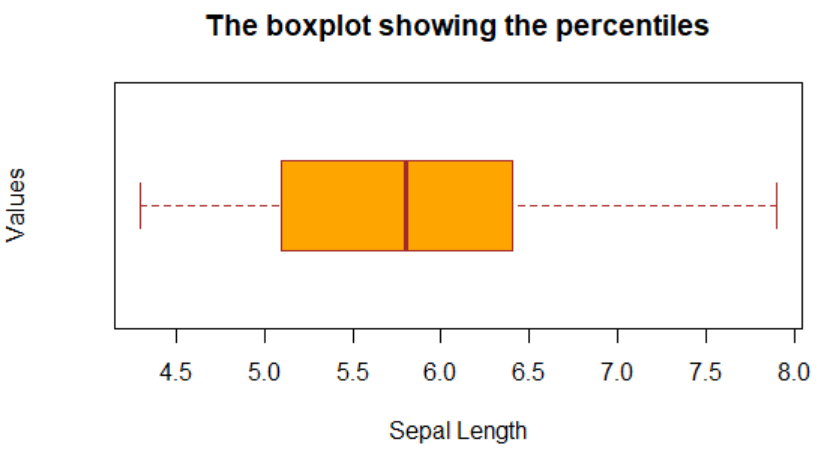
#plots a boxplot with labels
boxplot(iris$Sepal.Length,main='The boxplot showing the percentiles',col='Orange',ylab='Values',xlab='Sepal Length',border = 'brown',horizontal = T)
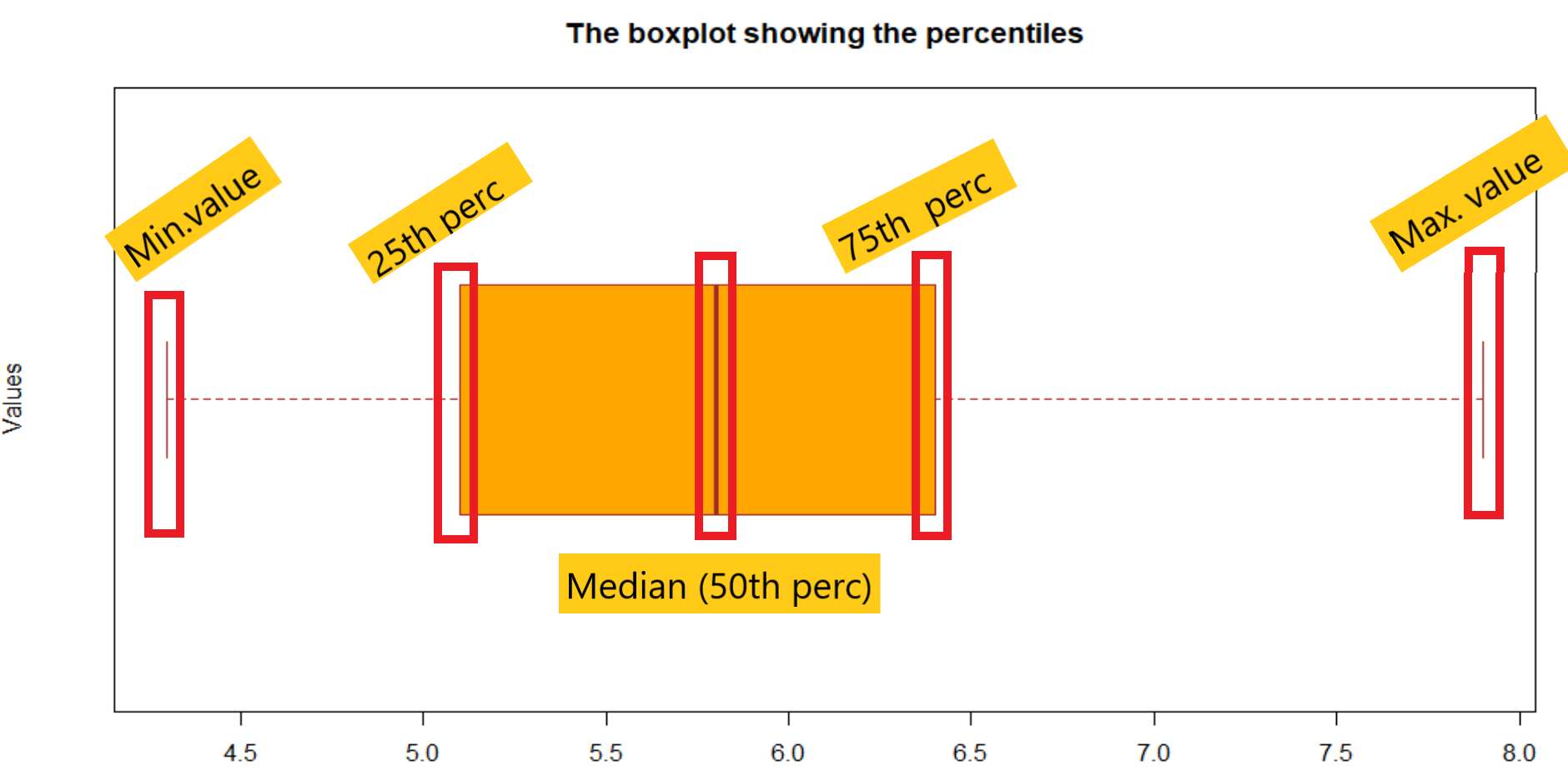
 一个箱型图可以展示数据的许多方面。下图中,我已经提到了由箱型图表示的特定值。这将为您节省一些时间,并以最好的方式促进您的理解。
一个箱型图可以展示数据的许多方面。下图中,我已经提到了由箱型图表示的特定值。这将为您节省一些时间,并以最好的方式促进您的理解。
在R中的Quantile()函数 - 收尾工作嗯,我觉得这是一篇较长的文章。我尽力通过多个例子和插图来解释和探索R中的quantile()函数在多个维度上的应用。quantile函数在数据分析中是最有用的函数,因为它能有效地提供关于给定数据的更多信息。
希望你对R中的quantile()函数周围的热议有了很好的理解。就目前而言,就这些了。我们将会带来更多美妙的函数和R编程的主题。在那之前请保重,祝你愉快地进行数据分析!
更多学习:R文档。

