Python损失函数完全指南:从理论到实战实现
在Python中,损失函数是任何机器学习模型中不可或缺的一部分。这些函数告诉我们模型的预测输出与实际输出的差异程度有多大。
有多种计算这个差异的方法。在本教程中,我们将介绍一些较为常见的损失函数。
在本教程中,我们将讨论以下四种损失函数:
- 均方差
- 均方根误差
- 平均绝对误差
- 交叉熵损失
在这四种损失函数中,前三种适用于回归模型,而最后一种适用于分类模型。
在Python中实施损失函数
让我们来看看如何在Python中实现这些损失函数。
1. 均方误差(Mean Square Error,简称MSE)
均方误差(MSE)是通过预测值与实际观察值之差的平方的平均值来计算的。数学上可以表示如下:
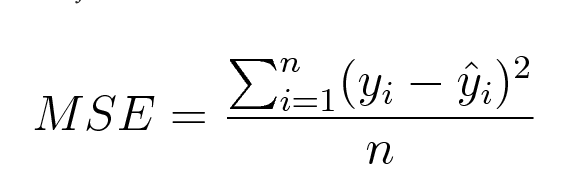
以下是用Python实现均方误差(MSE)的代码:
import numpy as np
def mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(mean_squared_error(act,pred))
输出:
0.04666666666666667
您还可以使用sklearn中的mean_squared_error来计算MSE。该函数的工作原理如下:
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred)
输出结果:
0.04666666666666667
2. 均方根误差(Root Mean Square Error, RMSE)
均方根误差(RMSE)是以均方误差的平方根计算而得。从数学上讲,我们可以表示为以下形式:
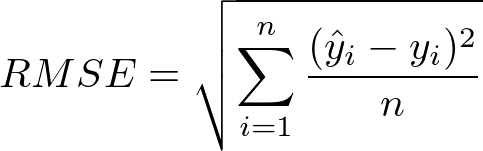
RMSE的Python实现如下:
这是文章《Python中的损失函数 – 简单实现》的第2部分(共4部分)。
import numpy as np
def root_mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
rmse_val = np.sqrt(mean_diff)
return rmse_val
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(root_mean_squared_error(act,pred))
输出结果:
0.21602468994692867
你也可以使用sklearn库中的mean_squared_error函数来计算均方根误差(RMSE)。下面我们来看看如何使用该函数实现RMSE计算。
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred, squared = False)
输出结果:
0.21602468994692867
如果将参数’squared’设置为True,则该函数返回均方误差(MSE)值。如果设置为False,则该函数返回均方根误差(RMSE)值。
3. 平均绝对误差(MAE)
平均绝对误差(MAE)是预测值与实际观测值之间绝对差异的平均值。从数学角度可以表示为:
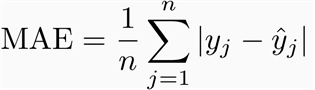
下面是MAE的Python实现:
import numpy as np
def mean_absolute_error(act, pred):
diff = pred - act
abs_diff = np.absolute(diff)
mean_diff = abs_diff.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act,pred)
输出结果:
0.20000000000000004
您还可以使用sklearn库中的mean_absolute_error函数(平均绝对误差函数)来计算MAE。
from sklearn.metrics import mean_absolute_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act, pred)
输出结果:
0.20000000000000004
4. Python 中的交叉熵损失函数
交叉熵损失函数也被称为负对数似然函数。它最常用于分类问题。分类问题是指将一个示例归类为两类以上之一的问题。
让我们来看看如何计算在二元分类问题中的错误率。
让我们考虑一个分类问题,模型试图对狗和猫进行分类。
以下是用Python编写的查找错误的代码。
from sklearn.metrics import log_loss
log_loss(["狗", "猫", "猫", "狗"],[[.1, .9], [.9, .1], [.8, .2], [.35, .65]])
输出:
0.21616187468057912
我们正在使用scikit-learn库中的log_loss方法。
函数调用中的第一个参数是每个输入样本的正确类别标签列表。第二个参数是模型预测的概率分布列表。
概率分布的格式如下:
[P(狗), P(猫)]
结论
本教程介绍了Python中的损失函数相关知识。我们详细讲解了用于回归和分类问题的各种损失函数。希望您在学习过程中有所收获!

