Java Stream distinct()函数用于去除重复项
Java Stream 的 distinct() 方法返回一个由不同元素组成的新流。在处理集合之前,将重复的元素删除是非常有用的。
Java Stream的distinct()方法
- The elements are compared using the equals() method. So it’s necessary that the stream elements have proper implementation of equals() method.
- If the stream is ordered, the encounter order is preserved. It means that the element occurring first will be present in the distinct elements stream.
- If the stream is unordered, then the resulting stream elements can be in any order.
- Stream distinct() is a stateful intermediate operation.
- Using distinct() with an ordered parallel stream can have poor performance because of significant buffering overhead. In that case, go with sequential stream processing.
使用distinct()函数删除重复元素。
让我们来看看如何使用流的distinct()方法从集合中删除重复元素。
jshell> List<Integer> list = List.of(1, 2, 3, 4, 3, 2, 1);
list ==> [1, 2, 3, 4, 3, 2, 1]
jshell> List<Integer> distinctInts = list.stream().distinct().collect(Collectors.toList());
distinctInts ==> [1, 2, 3, 4]

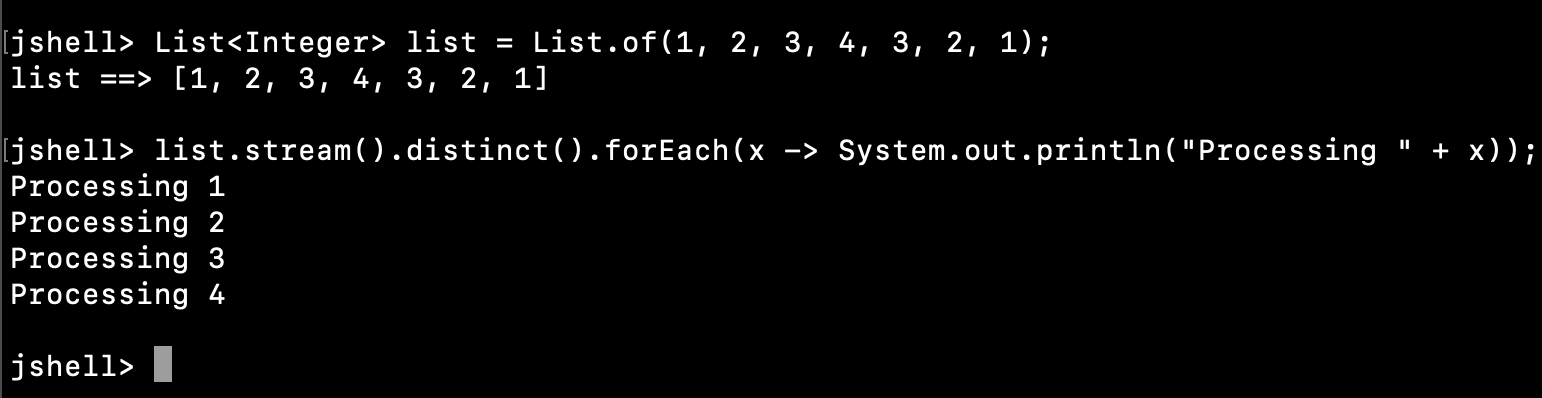
仅使用Stream的distinct()和forEach()方法来处理不重复的元素。
由于distinct()是一个中间操作,因此我们可以在它上面使用forEach()方法,仅处理唯一的元素。
jshell> List<Integer> list = List.of(1, 2, 3, 4, 3, 2, 1);
list ==> [1, 2, 3, 4, 3, 2, 1]
jshell> list.stream().distinct().forEach(x -> System.out.println("Processing " + x));
Processing 1
Processing 2
Processing 3
Processing 4
使用自定义对象的distinct()方法
让我们来看一个简单的例子,使用distinct()函数从列表中删除重复元素。
package com.Olivia.java;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class JavaStreamDistinct {
public static void main(String[] args) {
List<Data> dataList = new ArrayList<>();
dataList.add(new Data(10));
dataList.add(new Data(20));
dataList.add(new Data(10));
dataList.add(new Data(20));
System.out.println("Data List = "+dataList);
List<Data> uniqueDataList = dataList.stream().distinct().collect(Collectors.toList());
System.out.println("Unique Data List = "+uniqueDataList);
}
}
class Data {
private int id;
Data(int i) {
this.setId(i);
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return String.format("Data[%d]", this.id);
}
}
输出:
产出。
Data List = [Data[10], Data[20], Data[10], Data[20]]
Unique Data List = [Data[10], Data[20], Data[10], Data[20]]
distinct()方法没有删除重复元素。这是因为我们没有在Data类中实现equals()方法。所以使用了超类Object的equals()方法来识别相等的元素。Object类的equals()方法实现如下:
public boolean equals(Object obj) {
return (this == obj);
}
由于数据对象具有相同的ID,但它们引用的是不同的对象,所以它们被认为是不相等的。这就是为什么如果您计划在自定义对象中使用流的distinct()方法,实现equals()方法非常重要。请注意,Collection类API使用equals()和hashCode()方法来检查两个对象是否相等。因此最好为它们都提供实现。
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println("Data equals method");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Data other = (Data) obj;
if (id != other.id)
return false;
return true;
}
提示:您可以使用“Eclipse > Source > Generate equals() and hashCode()”菜单选项轻松生成equals()和hashCode()方法。添加equals()和hashCode()实现后的输出是:
Data List = [Data[10], Data[20], Data[10], Data[20]]
Data equals method
Data equals method
Unique Data List = [Data[10], Data[20
参考: 流distinct() API文档

