PythonでのReLu関数
Rectified Linear Activation Function(ReLU)は、ディープラーニングの世界で最も一般的な活性化関数の選択肢です。ReLUは最先端の結果を提供するばかりでなく、計算上も非常に効率的です。
Relu活性化関数の基本的なコンセプトは次のようになります:
Return 0 if the input is negative otherwise return the input as it is.
数学的には、次のように表現することができます。
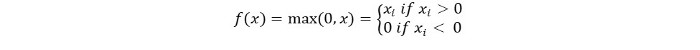
ReLUの擬似コードは以下の通りです。
if input > 0:
return input
else:
return 0
このチュートリアルでは、自分自身のReLu関数の実装方法、いくつかの欠点について学び、より良いバージョンのReLuについて学びます。
おすすめの読み物:機械学習のための線形代数学【パート1/2】
始めましょう!
PythonでReLu関数を実装する
PythonでReluの独自の実装を書きましょう。それを実装するために、組み込みのmax関数を使用します。
「ReLu」のコードは以下の通りです。
def relu(x):
return max(0.0, x)
機能を試すために、いくつかの入力で実行してみましょう。
x = 1.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -10.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 0.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 15.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -20.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
完全なコード
以下に完全なコードが示されています。
def relu(x):
return max(0.0, x)
x = 1.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -10.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 0.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 15.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -20.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
出力:
Applying Relu on (1.0) gives 1.0
Applying Relu on (-10.0) gives 0.0
Applying Relu on (0.0) gives 0.0
Applying Relu on (15.0) gives 15.0
Applying Relu on (-20.0) gives 0.0
ReLu関数の勾配
ReLU関数の勾配(導関数)がどうなるか見てみましょう。微分を行うと、以下の関数が得られます:
f'(x) = 1, x>=0
= 0, x<0
値が0未満のxにおいて、勾配が0であることがわかります。つまり、一部のニューロンの重みとバイアスは更新されていないことを意味します。これはトレーニングプロセスで問題となることがあります。
この問題を克服するために、リークReLU関数があります。次はそれについて学びましょう。
漏れるReLU関数
リーキーReLU関数は通常のReLU関数の派生です。負の値におけるゼロ勾配の問題に対処するため、リーキーReLUは負の入力に対してxの非常に小さな線形成分を与えます。
数学的には、リーキーReLUを次のように表現することができます。
f(x)= 0.01x, x<0
= x, x>=0
数学的に言えば:
- f(x)=1 (x<0)
- (αx)+1 (x>=0)(x)
ここでは、aは上記の0.01のような小さな定数です。
グラフィックで表すと、これは次のように示されます。
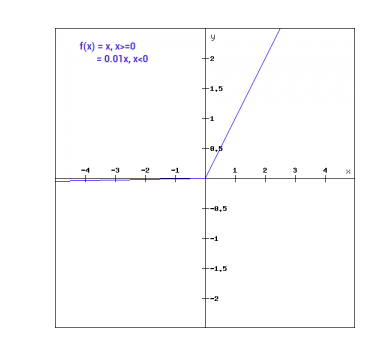
リーキーReLUの勾配
リーキーReLU関数の勾配を計算しましょう。勾配は以下のようになります。
f'(x) = 1, x>=0
= 0.01, x<0
この場合、負の入力に対する勾配はゼロではありません。つまり、すべてのニューロンが更新されることを意味します。
PythonでLeaky ReLuを実装する
Leaky ReLuの実装は以下の通りです。
def relu(x):
if x>0 :
return x
else :
return 0.01*x
現場の入力で試してみましょう。
x = 1.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -10.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 0.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 15.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -20.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
完全なコード
下記にLeaky ReLUの完全なコードが示されています。
def leaky_relu(x):
if x>0 :
return x
else :
return 0.01*x
x = 1.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -10.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 0.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 15.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -20.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
出力:
Applying Leaky Relu on (1.0) gives 1.0
Applying Leaky Relu on (-10.0) gives -0.1
Applying Leaky Relu on (0.0) gives 0.0
Applying Leaky Relu on (15.0) gives 15.0
Applying Leaky Relu on (-20.0) gives -0.2
結論
このチュートリアルでは、PythonでのReLu関数について説明しました。また、改善されたバージョンのReLu関数も見ました。Leaky ReLuは、ReLu関数の負の値における勾配ゼロの問題を解決するものです。

