Pythonを使用してscikit-learnを使ってデータを正規化する方法
はじめに
この記事では、scikit-learn(またはsklearnとも呼ばれる)を使用して、Pythonでデータの正規化を行ういくつかの異なる方法を試してみます。データを正規化すると、データのスケールが変更されます。データは一般的に0から1の範囲に再スケールされます。なぜなら、機械学習アルゴリズムは、異なる特徴がより小さなスケールである場合に、より良いパフォーマンスを発揮したり、より速く収束したりする傾向があるためです。データに対して機械学習モデルを訓練する前に、まずデータを正規化するのが一般的な慣行であり、可能性としてより良い、より速い結果が得られる場合があります。正規化により、訓練プロセスも特徴のスケールに対して感度が低くなり、訓練後の係数もより良くなります。
特徴のスケーリングによってトレーニングに適した特徴になるプロセスは、特徴のスケーリングと呼ばれています。
このチュートリアルは、Pythonバージョン3.9.13とscikit-learnバージョン1.0.2を使用してテストされました。
データを正規化するために、scikit-learnのpreprocessing.normalize()関数を使用する。
配列のようなデータセットを正規化するために、scikit-learnのpreprocessing.normalize()関数を使用できます。
normalize(正規化)関数は、ベクトルを個別に単位ノルムにスケーリングし、ベクトルの長さが1になるようにします。normalize(正規化)のデフォルトのノルムはL2であり、ユークリッドノルムとも呼ばれています。L2ノルムの式は、各値の二乗の合計の平方根です。normalize(正規化)関数の使用により、値は0から1の間になりますが、値を単に0から1の範囲にスケーリングするのとは異なります。
normalize()関数を使用して配列を正規化する
NumPyのnormalize()関数を使用することで、一次元のNumPy配列を正規化することができます。
sklearn.preprocessingモジュールをインポートしてください。
from sklearn import preprocessing
NumPyをインポートして、配列を作成する。
import numpy as np
x_array = np.array([2,3,5,6,7,4,8,7,6])
1次元の配列の場合、normalize()関数を使用してデータを行ごとに正規化します。
normalized_arr = preprocessing.normalize([x_array])
print(normalized_arr)
完全な例のコードを実行して、normalize()関数を使用してNumPy配列を正規化する方法をデモンストレーションしてください。
from sklearn import preprocessing
import numpy as np
x_array = np.array([2,3,5,6,7,4,8,7,6])
normalized_arr = preprocessing.normalize([x_array])
print(normalized_arr)
出力結果は:
[[0.11785113 0.1767767 0.29462783 0.35355339 0.41247896 0.23570226 0.47140452 0.41247896 0.35355339]]
出力は全ての値が0から1の範囲内にあることを示しています。出力の各値を二乗し、それを合計すると、結果は1、または1に非常に近くなります。
データフレームのnormalize()関数を使用して、カラムを正規化することで、カラムの値を標準化します。
パンダのデータフレームでは、特徴量は列であり、サンプルは行です。データフレームの列をNumPy配列に変換し、その配列内のデータを正規化することができます。
このセクションおよび続くセクションでの例は、カリフォルニア住宅データセットを使用しています。
例コードの最初の部分は、モジュールをインポートし、データセットを読み込み、データフレームを作成し、データセットの説明を表示します。
import numpy as np
from sklearn import preprocessing
from sklearn.datasets import fetch_california_housing
# create the DataFrame
california_housing = fetch_california_housing(as_frame=True)
# print the dataset description
print(california_housing.DESCR)
カリフォルニアの住宅オブジェクトを作成するために、as_frameパラメータをTrueに設定してください。
データセットの説明には以下の抜粋が含まれており、正規化する特徴を選ぶために使用することができます。
.. _california_housing_dataset: California Housing dataset ————————– **Data Set Characteristics:** :Number of Instances: 20640 :Number of Attributes: 8 numeric, predictive attributes and the target :Attribute Information: – MedInc median income in block group – HouseAge median house age in block group – AveRooms average number of rooms per household – AveBedrms average number of bedrooms per household – Population block group population – AveOccup average number of household members – Latitude block group latitude – Longitude block group longitude …
次に、列(特徴)を配列に変換し、それを印刷します。この例では、HouseAge列を使用します。
x_array = np.array(california_housing['HouseAge'])
print("HouseAge array: ",x_array)
最後に、normalize()関数を使用してデータを正規化し、結果の配列を出力します。
normalized_arr = preprocessing.normalize([x_array])
print("Normalized HouseAge array: ",normalized_arr)
ノーマライズ(normalize)関数を使用して、フィーチャを正規化する方法を示すために、完全な例を実行してください。
norm_feature.py → 正規化特徴量.py
from sklearn import preprocessing
import numpy as np
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
# print(california_housing.DESCR)
x_array = np.array(california_housing.data['HouseAge'])
print("HouseAge array: ",x_array)
normalized_arr = preprocessing.normalize([x_array])
print("Normalized HouseAge array: ",normalized_arr)
出力は:
HouseAge array: [41. 21. 52. … 17. 18. 16.] Normalized HouseAge array: [[0.00912272 0.00467261 0.01157028 … 0.00378259 0.0040051 0.00356009]]
以下の出力は、normalize() 関数が中央値住宅年齢の配列を変更し、値の二乗和の平方根が1に等しくなるようにしたことを示しています。つまり、L2ノルムを使用して値が単位長にスケーリングされました。
「normalize()」関数を使用して、行または列ごとにデータセットを正規化する。
特徴量または列を配列に変換せずにデータセットを正規化する場合、データは行ごとに正規化されます。normalize()関数のデフォルトの軸は1であり、各サンプルまたは行が正規化されます。
次の例は、デフォルトの軸を使用してCalifornia Housingデータセットを正規化する方法を示しています。
from sklearn import preprocessing
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
d = preprocessing.normalize(california_housing.data)
scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
print(scaled_df)
出力は次のとおりです:
MedInc HouseAge AveRooms … AveOccup Latitude Longitude 0 0.023848 0.117447 0.020007 … 0.007321 0.108510 -0.350136 1 0.003452 0.008734 0.002594 … 0.000877 0.015745 -0.050829 2 0.014092 0.100971 0.016093 … 0.005441 0.073495 -0.237359 3 0.009816 0.090449 0.010119 … 0.004432 0.065837 -0.212643 4 0.006612 0.089394 0.010799 … 0.003750 0.065069 -0.210162 … … … … … … … … 20635 0.001825 0.029242 0.005902 … 0.002995 0.046179 -0.141637 20636 0.006753 0.047539 0.016147 … 0.008247 0.104295 -0.320121 20637 0.001675 0.016746 0.005128 … 0.002291 0.038840 -0.119405 20638 0.002483 0.023932 0.007086 … 0.002823 0.052424 -0.161300 20639 0.001715 0.011486 0.003772 … 0.001879 0.028264 -0.087038 [20640 rows x 8 columns]
出力は、各サンプルごとに正規化されるように、行方向に値が正規化されていることを示しています。
ただし、軸を指定することで特徴による正規化が可能です。
次の例は、featureに対してaxis=0を使用してCalifornia Housingデータセットを正規化する方法を示しています。
from sklearn import preprocessing
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
d = preprocessing.normalize(california_housing.data, axis=0)
scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
print(scaled_df)
出力は以下の通りです。
MedInc HouseAge AveRooms … AveOccup Latitude Longitude 0 0.013440 0.009123 0.008148 … 0.001642 0.007386 -0.007114 1 0.013401 0.004673 0.007278 … 0.001356 0.007383 -0.007114 2 0.011716 0.011570 0.009670 … 0.001801 0.007381 -0.007115 3 0.009110 0.011570 0.006787 … 0.001638 0.007381 -0.007116 4 0.006209 0.011570 0.007329 … 0.001402 0.007381 -0.007116 … … … … … … … … 20635 0.002519 0.005563 0.005886 … 0.001646 0.007698 -0.007048 20636 0.004128 0.004005 0.007133 … 0.002007 0.007700 -0.007055 20637 0.002744 0.003783 0.006073 … 0.001495 0.007689 -0.007056 20638 0.003014 0.004005 0.006218 … 0.001365 0.007689 -0.007061 20639 0.003856 0.003560 0.006131 … 0.001682 0.007677 -0.007057 [20640 rows x 8 columns]
出力を調べると、HouseAge列の結果が、以前の例でHouseAge列を配列に変換し、正規化したときの出力と一致することに気付くでしょう。
scikit-learnのpreprocessing.MinMaxScaler()関数を使用して、データを正規化する。
各特徴量を正規化するために、scikit-learnのpreprocessing.MinMaxScaler()関数を使用することができます。データを範囲にスケーリングすることで、正規化が行われます。
MinMaxScaler()関数は、各フィーチャを個別にスケーリングし、値を指定した最小値と最大値に調整します。デフォルトでは、最小値は0、最大値は1です。
特徴値を0から1の間にスケーリングするための式は次の通りです。
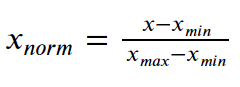
各エントリーから最小値を引き、その結果を範囲で除算します。範囲とは、最大値と最小値の差です。
以下の例は、MinMaxScaler()関数を使用してカリフォルニア住宅データセットを正規化する方法を示しています。
「minmax01.py」
from sklearn import preprocessing
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
scaler = preprocessing.MinMaxScaler()
d = scaler.fit_transform(california_housing.data)
scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
print(scaled_df)
出力は次のとおりです。
MedInc HouseAge AveRooms … AveOccup Latitude Longitude 0 0.539668 0.784314 0.043512 … 0.001499 0.567481 0.211155 1 0.538027 0.392157 0.038224 … 0.001141 0.565356 0.212151 2 0.466028 1.000000 0.052756 … 0.001698 0.564293 0.210159 3 0.354699 1.000000 0.035241 … 0.001493 0.564293 0.209163 4 0.230776 1.000000 0.038534 … 0.001198 0.564293 0.209163 … … … … … … … … 20635 0.073130 0.470588 0.029769 … 0.001503 0.737513 0.324701 20636 0.141853 0.333333 0.037344 … 0.001956 0.738576 0.312749 20637 0.082764 0.313725 0.030904 … 0.001314 0.732200 0.311753 20638 0.094295 0.333333 0.031783 … 0.001152 0.732200 0.301793 20639 0.130253 0.294118 0.031252 … 0.001549 0.725824 0.309761 [20640 rows x 8 columns]
出力は、値がデフォルトの最小値0と最大値1にスケーリングされていることを示しています。
以下の例では、スケーリングの最小値を0、最大値を2に指定することもできます。
from sklearn import preprocessing
import pandas as pd
from sklearn.datasets import fetch_california_housing
california_housing = fetch_california_housing(as_frame=True)
scaler = preprocessing.MinMaxScaler(feature_range=(0, 2))
d = scaler.fit_transform(california_housing.data)
scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
print(scaled_df)
出力は:
MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
0 1.079337 1.568627 0.087025 ... 0.002999 1.134963 0.422311
1 1.076054 0.784314 0.076448 ... 0.002281 1.130712 0.424303
2 0.932056 2.000000 0.105513 ... 0.003396 1.128587 0.420319
3 0.709397 2.000000 0.070482 ... 0.002987 1.128587 0.418327
4 0.461552 2.000000 0.077068 ... 0.002397 1.128587 0.418327
... ... ... ... ... ... ... ...
20635 0.146260 0.941176 0.059538 ... 0.003007 1.475027 0.649402
20636 0.283706 0.666667 0.074688 ... 0.003912 1.477152 0.625498
20637 0.165529 0.627451 0.061808 ... 0.002629 1.464400 0.623506
20638 0.188591 0.666667 0.063565 ... 0.002303 1.464400 0.603586
20639 0.260507 0.588235 0.062505 ... 0.003098 1.451647 0.619522
[20640 rows x 8 columns]
出力は、値が最小値0と最大値2にスケーリングされていることを示しています。
結論
この記事では、サンプル(行)と特徴量(列)によってデータを異なる方法で正規化するために、scikit-learnの2つの関数を使用しました。他の機械学習のトピックについて学習を続けましょう。

