PythonでのK-最近傍法(K-Nearest Neighbors、KNN)
k最近傍法(kNN)は、分類および回帰のタスクの両方を処理するために使用される教師あり機械学習の手法です。私はKNNを現実の生活から生まれたアルゴリズムと見なしています。人々は周りの人々から影響を受ける傾向があります。
K-最近傍法アルゴリズムの背後にある考え方
私たちの行動は、一緒に育った仲間によって形作られます。また、両親も私たちの個性をさまざまな方法で形作ります。もしスポーツを楽しむ人々の中で育ったとしたら、スポーツを愛するようになる可能性が非常に高いです。もちろん、例外もあります。KNNも同様です。
-
- もし親友がいて、ほとんどの時間を一緒に過ごすなら、共通の興味を持ち、同じものを愛するようになります。それがk=1のkNNです。
- もし常に5人のグループと一緒に過ごすなら、グループのそれぞれが行動に影響を与え、最終的には5人の平均となります。それがk=5のkNNです。
kNN分類器は、最頻出クラスの原則を用いてデータポイントのクラスを特定します。kが5に設定されている場合、5つの最近傍点のクラスが調べられます。予測は優勢なクラスに応じて行われます。同様に、kNN回帰では5つの最近傍位置の平均値を取ります。
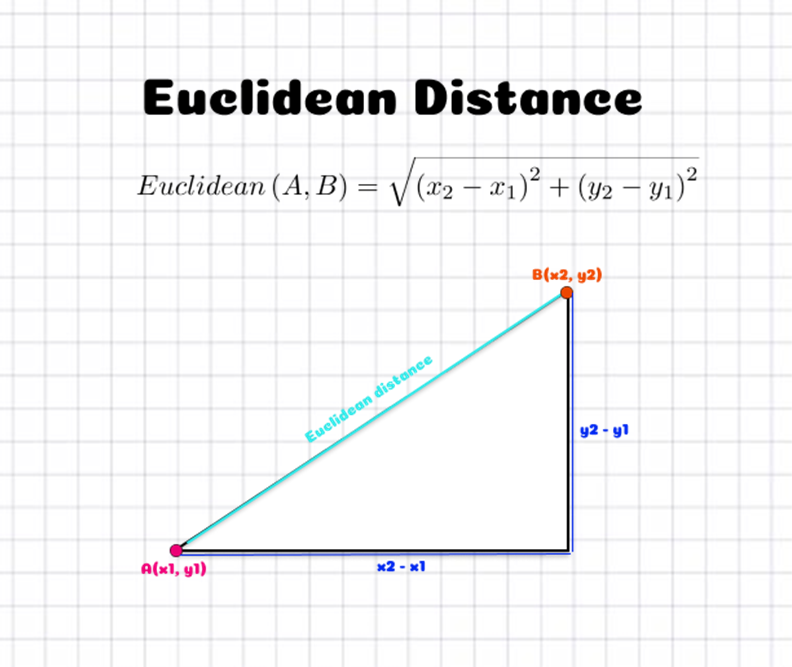
私たちは、近いとされる人々を目撃しますが、データポイントがどのように近いと考えられるのかを確認しますか?データポイント間の距離は測定されます。距離を推定するためのさまざまな技術があります。ユークリッド距離(p=2のミンコフスキー距離)は、最も頻繁に使用される距離の測定方法の1つです。以下の図は、2次元空間における2つの点間のユークリッド距離を計算する方法を説明しています。それは、位置のx座標とy座標の差の2乗を使用して決定されます。
PythonでKNNアルゴリズムを実装
では、PythonでのKNNの実装に入りましょう。コードを分解してより理解しやすくするためのステップを説明します。
1. モジュールをインポートする
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
2. データセットの作成
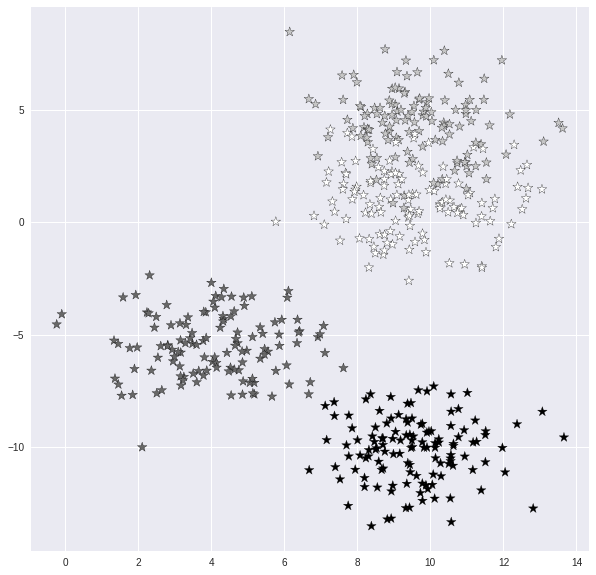
Scikit-learnには、機械学習アルゴリズムのテストに適した合成データセットを作成するための多くのツールがあります。私はmake_blobsメソッドを利用します。
X, y = make_blobs(n_samples = 500, n_features = 2, centers = 4,cluster_std = 1.5, random_state = 4)
このコードは、2つの特徴量を持つ4つのクラスに分割された500のサンプルデータセットを生成します。関連するパラメータを使用して、サンプル、特徴量、クラスの数を簡単に変更することができます。また、各クラス(またはクラスタ)の分布も変更することができます。
3. データセットをビジュアライズする
plt.style.use('seaborn')
plt.figure(figsize = (10,10))
plt.scatter(X[:,0], X[:,1], c=y, marker= '*',s=100,edgecolors='black')
plt.show()
4. データをトレーニング用とテスト用のデータセットに分割する
あらゆる教師あり機械学習手法において、データセットをトレーニングセットとテストセットに分割することが重要です。まず最初にモデルをトレーニングし、その後にデータセットのさまざまな部分でテストを行います。データを分けなければ、モデルは既に知っているデータで試験を行うだけになります。train_test_splitメソッドを使用することで、簡単にテストを分離することができます。
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
列車サイズとテストサイズのオプションにより、それぞれ訓練セットとテストセットの元データの利用量を決定することができます。デフォルトの分割は訓練セットに75%、テストセットに25%です。
5. KNN分類器の実装
その後、kNN分類器オブジェクトを構築します。kの値の関連性を示すために、k値が1と5の2つの分類器を開発します。モデルはトレーニングセットを使用して訓練されます。kの値はn_neighbors引数を使用して選択されますが、デフォルト値は5なので明示的に指定する必要はありません。
knn5 = KNeighborsClassifier(n_neighbors = 5)
knn1 = KNeighborsClassifier(n_neighbors=1)
6. KNN分類器の予測
そして、テストセットでターゲットの値を予測し、実際の値と比較します。
knn5.fit(X_train, y_train)
knn1.fit(X_train, y_train)
y_pred_5 = knn5.predict(X_test)
y_pred_1 = knn1.predict(X_test)
7. k値ごとの予測精度を予測します。
from sklearn.metrics import accuracy_score
print("Accuracy with k=5", accuracy_score(y_test, y_pred_5)*100)
print("Accuracy with k=1", accuracy_score(y_test, y_pred_1)*100)
kの値に関する正確性は以下のように表れます:
Accuracy with k=5 93.60000000000001
Accuracy with k=1 90.4
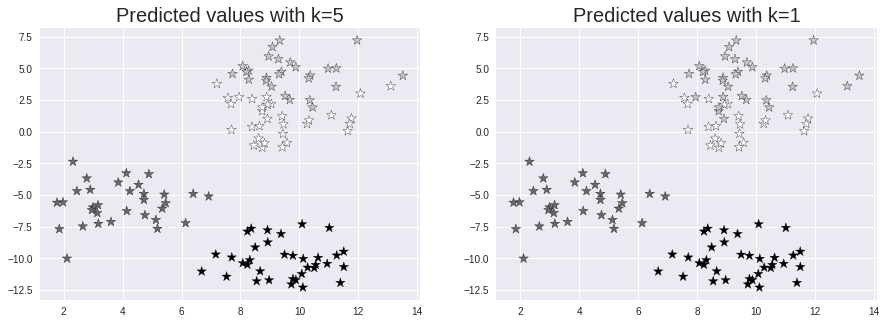
8. 予測をビジュアル化する (Yosoku o bijuaruka suru)
k=5とk=1の場合に、テストセットと予測値を見て、kの値の影響を確認しましょう。
plt.figure(figsize = (15,5))
plt.subplot(1,2,1)
plt.scatter(X_test[:,0], X_test[:,1], c=y_pred_5, marker= '*', s=100,edgecolors='black')
plt.title("Predicted values with k=5", fontsize=20)
plt.subplot(1,2,2)
plt.scatter(X_test[:,0], X_test[:,1], c=y_pred_1, marker= '*', s=100,edgecolors='black')
plt.title("Predicted values with k=1", fontsize=20)
plt.show()
「KNNを実装するための最適なk値を見つける方法」
-
- k=1:モデルは狭すぎて適切に一般化されていません。ノイズに対しても高い感度を持っています。モデルは学習データセットで新しい未知のデータ点を高精度で予測しますが、新鮮な未知のデータ点に対しては予測力が乏しいです。その結果、過学習したモデルになりがちです。
k=100:モデルは広範であり、学習データセットとテストデータセットの両方で信頼性がありません。この状況をアンダーフィッティングと呼びます。
KNN(k最近傍法)アルゴリズムの制約
KNNは理解しやすい直感的なアルゴリズムです。予測を生成するために内部の機械学習モデルに依存しません。KNNは、単に何カテゴリがあるかを知る必要がある分類手法です(1つ以上)。これは、他のカテゴリがいくつあるかを知る必要なく、新しいカテゴリを迅速に追加すべきかどうかを評価できることを意味します。
このシンプルさの欠点は、新しい病気のような予測できないことです。KNNは、健康な人口における珍しいアイテムの頻度を知らないため、それを達成することができません。
KNNはテストセットで高い精度を達成するものの、時間とメモリの面では遅くて高価です。予測のためには、トレーニングデータセット全体を格納するために相当な量のメモリが必要です。さらに、ユークリッド距離は大きな値を持つデータセットの特性を常に小さな値を持つ特性よりも重視するため、非常に感度が高いです。
最後に、これまで議論してきたことを考慮に入れると、KNNは大次元のデータセットには最適ではないことを忘れてはなりません。
結論
KNNアルゴリズムの理解がより深まったことを願っています。KNNが予測を生成するために完全なデータセットを保存する様々なアイデアを見てきました。
KNNは、予測を行うために学習モデルを使用しないいくつかの怠惰学習アルゴリズムの一つです。KNNは、入力された観測値と既に利用可能なデータの類似性を平均化することで、リアルタイムで予測を作成します。
お読みいただき、ありがとうございます!

