PDFや画像のサーバーサイドでのOCRの実行方法は?
はじめに
OCR、または「光学文字認識」は、主にスキャンされたイメージのテキストを選択可能でコピー可能な、エンコードされ、埋め込まれたテキストに変換するために使用されます。多くの現代のデスクトップおよびモバイルアプリケーションやスキャナーソフトウェアスタックには、OCR機能が組み込まれています。また、ほとんどのPDFにはテキストが埋め込まれています。ただし、自動的に抽出できない大量の非埋め込みテキストを含む文書や画像に出会うこともあります。
この場合、オープンソースのツールのパイプラインを使用して、自動的にOCRを行うことができます。これは特に、テキストを抽出する必要があるWebアプリケーションに文書や画像を読み込む場合や、全文をインデックス化する必要がある大量の文書を扱っている場合に非常に便利です。
このチュートリアルでは、Ghostscript、Tesseract、およびPDFtkを使用してOCRパイプラインのセットアップ方法を説明します。さらに、この基本機能の代わりまたは追加として使用できる他のツールについても紹介します。
前提条件
これらのツールはほとんどのプラットフォームで利用可能です。このチュートリアルでは、Ubuntu 22.04 サーバーへのインストール手順について説明します。当ガイド「Ubuntu 22.04の初期サーバーセットアップ」に従ってください。
ステップ1 – Ghostscript、Tesseract、およびPDFtkのインストール
OCRはPDF(画像を含んでおり、時には画像として表示される)および単独の画像の両方で実行することができます。PDFと一緒に作業する場合は追加の手順が必要ですが、画像だけで作業する場合はそれをスキップすることができます。
エンドツーエンドのパイプラインには、3つのツールが必要です。Ghostscriptは、あらゆる種類のPDFからイメージへの変換やその逆を処理するツールです(元々はPDFの前身技術であるPostscriptのインタプリタとして作成されました)。TesseractはオープンソースのOCRエンジンであり、Ghostscriptと同様に1980年代から継続的に開発されています。PDFtkは個々のページからPDFを切り出したり再構築するための小さなユーティリティです。
すべての3つのアプリケーションは、Ubuntuのデフォルトのリポジトリで利用可能であり、aptパッケージマネージャーを使用してインストールすることができます。パッケージソースをapt updateで更新し、その後apt installを使用してインストールしてください。
- sudo apt update
- sudo apt install pdftk ghostscript tesseract-ocr x11-utils
現在、各アプリケーションごとに確認できる3つの新しいコマンドが表示されるはずです。
- which pdftk
/usr/bin/pdftk
- which gs
/usr/bin/gs
- which tesseract
/usr/bin/tesseract
次のステップでOCRを実行するために、これらのコマンドを使用します。 (Tsugi no suteppu de OCR wo jikkō suru tame ni, korera no komando wo shiyō shimasu.)
ステップ2 – PDFを画像に変換し、Tesseractを実行する。
すでにOCRを行いたいPDFがない場合は、埋め込まれたテキストがないスキャンされたサンプルPDFをダウンロードして、このチュートリアルに沿って進めることができます。PDFをサーバーにダウンロードするには、curlを使用し、-Oフラグで現在のディレクトリに同じファイル名で保存します。
- curl -O https://deved-images.nyc3.cdn.digitaloceanspaces.com/server-ocr/OCR-sample-paper.pdf
もし1つ以上のPDFファイルで作業している場合、OCRのソースとして使用する前にそれらを個別の画像に変換する必要があります。これはGhostscriptコマンドを使用して行うことができます。DPI、カラースペース、および寸法に関する一貫性を維持するために、追加のパラメータを含める必要があります。まず、このプロセスで作成されたファイルのための作業用の出力ディレクトリを作成し、次にgsを実行します。
- mkdir output
- gs -o output/%05d.png -sDEVICE=png16m -r300 -dPDFFitPage=true OCR-sample-paper.pdf
このgsコマンドは、-oフラグを使用して、コマンドの残りの部分よりも先に出力パスを指定します。%05dはグローススクリプトがネイティブで理解するわかりにくいシェル構文であり、この場合は、入力PDFから出力PNGファイルを自動的に増分される5桁の番号で名前付けすることを意味します。他の古いコマンドラインアプリケーションでもこれを使用することがあります。一部のPNGフォーマット構文とDPIの-r300を追加した後、OCR-sample-paper.pdfまたは選択した入力ファイルへのパスを指定してください。
GhostscriptはPDFの各ページを個別に出力します。
Processing pages 1 through 14. Page 1 Page 2 Page 3 Page 4 Page 5 …
終わったら、出力ディレクトリの内容を確認できます。
- ls output
00001.png 00003.png 00005.png 00007.png 00009.png 00011.png 00013.png 00002.png 00004.png 00006.png 00008.png 00010.png 00012.png 00014.png
次に、作成した画像を個別のPDFページに戻すために、シェルのループを使用します。このとき、テキストが埋め込まれたPDFページにします。シェルのループは他のプログラミング言語のループと同様に振る舞います。各部分をセミコロンで区切って単一のコマンドにまとめることができます。最後にdoneで終了します。
- for png in $(ls output); do tesseract -l eng output/$png output/$(echo $png | sed -e “s/\.png//g”) pdf; done
コマンドがループしている間、テキストがシェルに出力されます。
Tesseract Open Source OCR Engine v4.1.1 with Leptonica Tesseract Open Source OCR Engine v4.1.1 with Leptonica Tesseract Open Source OCR Engine v4.1.1 with Leptonica Tesseract Open Source OCR Engine v4.1.1 with Leptonica …
以下のように日本語で書き換えました。:
Tesseractの構文自体は以下のコンポーネントです:tesseract -l 言語 入力ファイル名 出力基本ファイル名 [pdf]。もし-l 言語が省略された場合、Tesseractはデフォルトで英語の言語モデルを使用します。また、pdfが省略された場合、Tesseractは入力画像とは別に識別されたテキストを出力し、PDFではなくします。このコマンドに追加されたsed構文は、Tesseractに正しいパスを提供し、出力ファイルを.pdfにリネームする際に.pngの拡張子を削除するようにします。
Note
公式のドキュメントには、さらに多くのTesseractコマンドラインの例が見つかります。
Tesseractを実行した後は、出力ディレクトリをもう一度確認してください。
- ls output
新しく作成されたすべてのPDFページが表示されます。
00001.pdf 00003.pdf 00005.pdf 00007.pdf 00009.pdf 00011.pdf 00013.pdf 00001.png 00003.png 00005.png 00007.png 00009.png 00011.png 00013.png 00002.pdf 00004.pdf 00006.pdf 00008.pdf 00010.pdf 00012.pdf 00014.pdf 00002.png 00004.png 00006.png 00008.png 00010.png 00012.png 00014.png
出力イメージが必要な場合は、このチュートリアルの最後のステップに進んで、一括テキスト抽出オプションについてさらに学ぶことができます。PDFを使用している場合は、次のステップで再構築して最終的な準備を行います。
ステップ3(オプション) – 画像出力からPDFを再構築します。
もし最後のステップでPDFを入力として使用した場合、PDFtkとGhostscriptを再度使用してTesseractによって生成された個々のページを結合する必要があります。それらは順番に番号が付けられているため、シェル構文を使用してpdftkのcatコマンドにファイルの並べたリストを渡して結合することができます。
- pdftk output/*.pdf cat output joined.pdf
現在、結果のTesseractから再構築したPDFが「joined.pdf」という名前で1つ作成されました。残る唯一のステップは、Ghostscriptを使用してPDFを再フォーマットすることです。これは重要です。なぜなら、Tesseractは常に正確なPDFの寸法を保証しているわけではないからです。新しいPDFは現在、最適化されていないため、入力よりもはるかに大きいです。GhostscriptはPDFを正確な仕様に再レンダリングするためのはるかに強力なツールです。最後に、”joined.pdf”に対して1つのgsコマンドを実行してください。
- gs -sDEVICE=pdfwrite -sPAPERSIZE=letter -dFIXEDMEDIA -dPDFFitPage -o final.pdf joined.pdf
このコマンドに関しては、PDFの仕様の違反についていくつかの警告が表示される場合がありますが、これは通常のことです。Ghostscriptは他のツールよりもPDFの規格に厳格であり、ほとんどのPDFはほとんどのビューアで表示されます。
-sDEVICE=pdfwrite -sPAPERSIZE=letter -dFIXEDMEDIA -dPDFFitPageというパラメータは、PDFの寸法を確定させるためにすべて使用されます。異なるページフォーマットで作業している場合は、sPAPERSIZE=letterを変更する必要があるかもしれません。gsコマンドに提供された-o final.pdfファイル名は、完成した出力の名前になります。
あなたのOCRが成功したかどうかをテストするために、デスクトップアプリケーションでPDFをローカルに開くか、pdftotextのようなコマンドラインアプリケーションを使用してドキュメントから埋め込まれたテキストをダンプすることができます。
Ubuntuでは、pdftotextをインストールすることができます。これには、PDFをコマンドラインで操作するためのいくつかのツールが含まれているpoppler-utilsというパッケージを使用します。
- sudo apt install poppler-utils
次に、新しいPDFファイルにpdftotextを実行してください。
- pdftotext final.pdf
新しいファイル、final.txtが作成されます。headのようなツールで、このファイルの内容をプレビューできます。
- head final.txt
Pakistan Journal of Applied Economics (1983) vol. II, no. 2 (167—180) THE MEASUREMENT OF FARM-SPECIFIC TECHNICAL EFFICIENCY K. P. KALIRAJAN and J. C, FLINN* Measures of technical efficiency were estimated using a stochastic translog production frontier for a sample of rainfed rice farmers in Bicol, Philippines. These estimates were farm specific as opposed to being based on deviations from an average sample efficiency. A wide variation in the level of technical
入力ファイルからテキストの流れを受け取る必要があります。それは順序が逆であったり、奇妙な書式文字が含まれていたりするかもしれませんが、一度にテキストを排出するときにはそれが自然です。重要なことは、ドキュメントに埋め込まれたテキストが含まれているということです。この時点で、作業中のイメージやPDFページを含む出力ディレクトリを削除しても構いません。それらのイメージはもはや必要ありません。
現在、3つのツールと4つのコマンドを使用したエンドツーエンドのPDF OCRパイプラインがあります。これらはスタンドアロンのスクリプトに結合することもできますし、別のアプリケーションに統合することもできますし、必要に応じてインタラクティブに実行することもできます。これは個々のPDF文書に対する完全なソリューションです。次のステップでは、データテーブルのフォーマットや大量のテキスト抽出のための追加オプションを確認します。
ステップ4(オプション)- OCR後のドキュメントからCSVテーブルを抽出する。
画像またはPDFをOCR処理した後、任意で表形式またはスプレッドシート形式のデータをCSVファイルに抽出することもできます。これは古いデータソースや科学論文との作業時に特に便利です。
この機能を提供する2つのツールがありますが、どちらも同様な機能を備えています。Javaで書かれたTabulaとPythonで書かれたCamelotです。
タブラ
UbuntuでTabulaをsnapパッケージとしてインストールするには、snap installを使用します。
- sudo snap install tabula
このチュートリアルで使用されているサンプルPDFを視覚的に検査すると、6ページの中央にテーブルが見つかります。
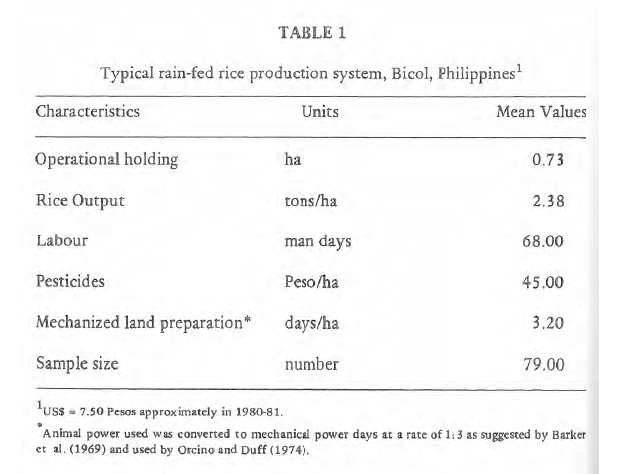
したがって、最終的なPDFのページ6から表を抽出するために、あなたはtabulaを実行し、出力結果をtest.csvという新しいファイルにリダイレクトします。
- tabula -p 6 final.pdf > test.csv
test.csv内のテーブル検出の品質を確認してください。それをExcelなどのスプレッドシートプログラムや他のデータ分析スクリプトの入力として使用できるはずです。
キャメロット
CamelotはPythonのライブラリであり、Pythonとpip(Pythonパッケージマネージャー)をインストールしている必要があります。Pythonをまだインストールしていない場合は、「Ubuntu 22.04 ServerにPython 3をインストールしてプログラミング環境をセットアップする方法」の最初のステップを参照してください。
次に、Camelotをpip installを使用してインストールすると同時に、その依存関係であるopencvも一緒にインストールしてください。
- sudo pip install camelot-py opencv-python-headless ghostscript
その後、再びパスとファイルタイプを指定して、final.pdfを入力としてcamelotをPDF上で実行することができます。
- camelot -p 6 -f csv -o test.csv stream final.pdf
必要に応じて、キャメロットのドキュメンテーションを参照して抽出を微調整できます。
このチュートリアルの最後の選択肢として、いくつかの他のOCRソリューションをレビューします。
ステップ5(オプション)- 大量抽出のために他のOCRソリューションの使用
Tesseractは最も長く開発されたオープンソースのOCRツールであり、最も幅広い出力形式をサポートしていますが、サーバーサイドのOCRを実行するためにはいくつかの他のオプションも存在します。EasyOCRはより新しいオープンソースのOCRエンジンであり、より積極的に開発されており、GPU上で実行することでより高速かつ正確な結果を提供することができます。ただし、EasyOCRはPDF出力をサポートしていないため、入力文書の再構築が困難であり、主に大量の生のテキストを出力するために有用です。
EasyOCRはPythonのライブラリであり、Pythonとパッケージマネージャーであるpipをインストールしている必要があります。Pythonのインストールがまだの場合、Ubuntu 22.04 ServerでPython 3をインストールし、プログラミング環境を構築する手順の最初のステップを参照してください。
次に、pip installコマンドを使用してEasyOCRをインストールしてください。
- sudo pip install easyocr
EasyOCRをインストールした後は、Pythonスクリプト内のライブラリとして使用することもできますし、easyocrコマンドを使って直接コマンドラインから呼び出すこともできます。EasyOCRのサンプルコマンドは次のようになります。
- easyocr -l ch_sim en -f image.jpg –detail=1 –gpu=True
EasyOCRは、複数の言語モデルを同時に読み込んでマルチリンガルOCRを実行することができます。-lフラグに続けて複数の言語を指定することができます。この場合、簡体字中国語はch_sim、英語はenです。-f image.jpgは入力ファイルのパスです。–detail=1を使用すると、抽出されたテキストの位置を参照する必要がある場合に、バウンディングボックスの座標が出力されます。また、–detail=0で実行することで、この情報を省略することもできます。
「-gpu=True」フラグはオプションであり、GPU環境が設定されている場合、より効率的な抽出のためにCUDAコードパスを使用しようとします。
結論
このチュートリアルでは、成熟したオープンソースツールを使用してOCRパイプラインを作成しました。このパイプラインは他のアプリケーションスタックに組み込むか、ウェブサービスとして公開できます。また、これらのツールの細かい調整に使用できる構文やオプションについても確認し、CSVテーブルの抽出や大規模なテキスト抽出のための他のOCRオプションについても考慮しました。
OCRは理解されて広く利用されている技術です。必要な場合には使用することができます。しかし、キーターンキーのOCR実装は多くの場合、有料のデスクトップソフトウェアに制限されています。必要な場所にOCRツールを展開できることは非常に便利です。次に、関連するトピックエリアを再確認するために、機械学習入門を読んでも良いかもしれません。

