DataFrameをCSVに変換するためのPandasのto_csv()
PandasのDataFrameのto_csv()関数は、DataFrameをCSVデータに変換します。CSVデータをファイルに書き込む場合は、ファイルオブジェクトを渡すことができます。それ以外の場合は、CSVデータが文字列形式で返されます。
パンダのデータフレームto_csv()の文法
DataFrameのto_csv()関数の文法は以下のようになります。
def to_csv(
self,
path_or_buf=None,
sep=",",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode="w",
encoding=None,
compression="infer",
quoting=None,
quotechar='"',
line_terminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal=".",
)
重要なパラメータのいくつかは次のとおりです。
- path_or_buf: the file object to write the CSV data. If this argument is not provided, the CSV data is returned as a string.
- sep: the delimiter for the CSV data. It should be a string of length 1, the default is a comma.
- na_rep: string representing null or missing values, default is empty string.
- columns: a sequence to specify the columns to include in the CSV output.
- header: the allowed values are boolean or a list of string, default is True. If False, the column names are not written in the output. If a list of string, it’s used to write the column names. The length of the list of string should be the same as the number of columns being written in the CSV file.
- index: if True, index is included in the CSV data. If False, the index value is not written in the CSV output.
- index_label: used to specify the column name for index.
パンダのデータフレームをCSVに変換する例
DataFrameをCSVデータに変換するためにto_csv()関数を使用する一般的な例を見てみましょう。
1. データフレームをCSV形式の文字列に変換する
import pandas as pd
d1 = {'Name': ['Pankaj', 'Meghna'], 'ID': [1, 2], 'Role': ['CEO', 'CTO']}
df = pd.DataFrame(d1)
print('DataFrame:\n', df)
# default CSV
csv_data = df.to_csv()
print('\nCSV String:\n', csv_data)
出力:
DataFrame:
Name ID Role
0 Pankaj 1 CEO
1 Meghna 2 CTO
CSV String:
,Name,ID,Role
0,Pankaj,1,CEO
1,Meghna,2,CTO
2. CSV出力の区切り文字を指定
csv_data = df.to_csv(sep='|')
print(csv_data)
出力:
|Name|ID|Role
0|Pankaj|1|CEO
1|Meghna|2|CTO
もし指定された区切り文字の長さが1ではない場合、TypeError: “delimiter”は1文字の文字列でなければなりませんというエラーが発生します。
3.CSV出力のために、一部の列のみ選択します。
csv_data = df.to_csv(columns=['Name', 'ID'])
print(csv_data)
出力:
,Name,ID
0,Pankaj,1
1,Meghna,2
インデックスは有効な列とは見なされないことに注意してください。
4. CSV出力時にヘッダー行を無視する。
csv_data = df.to_csv(header=False)
print(csv_data)
出力:
0,Pankaj,1,CEO
1,Meghna,2,CTO
5. CSVにカスタムの列名を設定する。
csv_data = df.to_csv(header=['NAME', 'ID', 'ROLE'])
print(csv_data)
出力:
,NAME,ID,ROLE
0,Pankaj,1,CEO
1,Meghna,2,CTO
再び、インデックスはDataFrameオブジェクトの列として考えられていません。
6. CSV出力において、インデックス列を省略する。
csv_data = df.to_csv(index=False)
print(csv_data)
出力:
Name,ID,Role
Pankaj,1,CEO
Meghna,2,CTO
7. CSV でインデックス列の名前を設定する。
csv_data = df.to_csv(index_label='Sl No.')
print(csv_data)
出力:
Sl No.,Name,ID,Role
0,Pankaj,1,CEO
1,Meghna,2,CTO
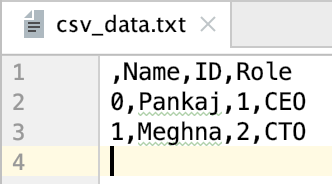
8. DataFrameをCSVファイルに変換する。
with open('csv_data.txt', 'w') as csv_file:
df.to_csv(path_or_buf=csv_file)
9. CSV出力におけるNull、NA、または欠損データの表現
import pandas as pd
d1 = {'Name': ['Pankaj', 'Meghna'], 'ID': [1, pd.NaT], 'Role': [pd.NaT, 'CTO']}
df = pd.DataFrame(d1)
print('DataFrame:\n', df)
csv_data = df.to_csv()
print('\nCSV String:\n', csv_data)
csv_data = df.to_csv(na_rep="None")
print('CSV String with Null Data Representation:\n', csv_data)
結果:
DataFrame:
Name ID Role
0 Pankaj 1 NaT
1 Meghna NaT CTO
CSV String:
,Name,ID,Role
0,Pankaj,1,
1,Meghna,,CTO
CSV String with Null Data Representation:
,Name,ID,Role
0,Pankaj,1,None
1,Meghna,None,CTO
参考文献
- Pandas read_csv() – Reading CSV File to DataFrame
- Python Pandas Module Tutorial
- DataFrame to_csv() API Doc

