探索的データ分析(EDA):Pythonの関数を使用して
前の記事では、グラフを使ったEDAの方法を見てきました。この記事では、PythonでのExploratory Data Analysis(探索的データ分析)に使用されるPython関数に焦点を当てます。私たちが皆知っているように、EDAはデータの簡単な理解を提供するためにどれだけ重要かを示しています。ですので、時間を無駄にせずに始めましょう!
探索的データ分析 – EDA
- EDA is applied to investigate the data and summarize the key insights.
- It will give you the basic understanding of your data, it’s distribution, null values and much more.
- You can either explore data using graphs or through some python functions.
- There will be two type of analysis. Univariate and Bivariate. In the univariate, you will be analyzing a single attribute. But in the bivariate, you will be analyzing an attribute with the target attribute.
- In the non-graphical approach, you will be using functions such as shape, summary, describe, isnull, info, datatypes and more.
- In the graphical approach, you will be using plots such as scatter, box, bar, density and correlation plots.
データをロードする
まずは、最初にやるべきことですね。EDA(探索的データ解析)を行うために、タイタニックのデータセットをPythonに読み込みます。
#Load the required libraries
import pandas as pd
import numpy as np
import seaborn as sns
#Load the data
df = pd.read_csv('titanic.csv')
#View the data
df.head()
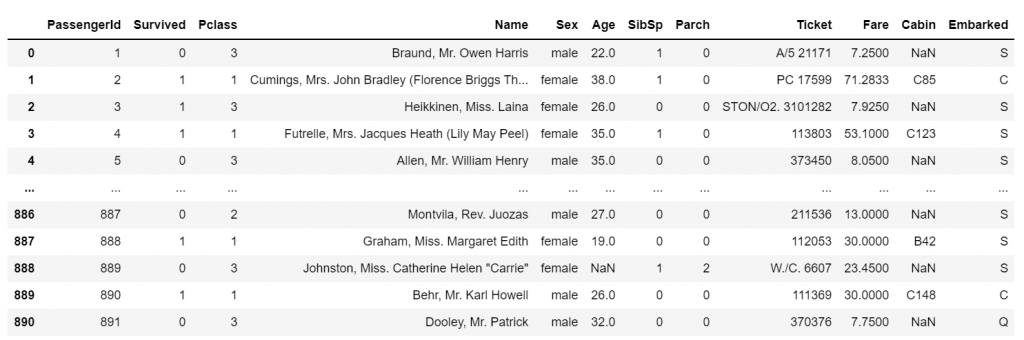
私たちのデータは探索の準備ができています!
データに関する基本的な情報- EDA
データセットに関する基本情報を提供するdf.info()関数です。どんなデータであれ、その情報を知ることから始めることは良いです。では、私たちのデータでどのように機能するか見てみましょう。
#Basic information
df.info()
#Describe the data
df.describe()
- Describe the data – Descriptive statistics.
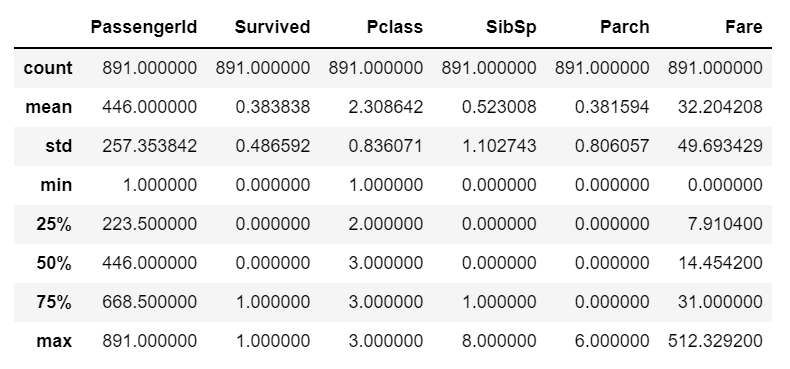
この機能を使用することで、上記の出力に示されるように、ヌル値の数、データ型、およびメモリ使用量、そして記述統計情報を確認することができます。
2. 重複した値
データに重複する値がある場合は、df.duplicate.sum() 関数を使用して、重複した値の合計を表示することができます。データ内に重複する値がある場合、重複する値の数も表示されます。
#Find the duplicates
df.duplicated().sum()
0. 私は日本語を自然にパラフレーズしてください。一つのオプションだけで構いません。
まあ、その関数は「0」を返しました。これは、私たちのデータセットに重複する値が存在しないことを意味し、知ることは非常に良いことです。
3. データ内の特異・ユニークな値
Pythonのunique()関数を使用することで、特定の列内のユニークな値の数を見つけることができます。
#unique values
df['Pclass'].unique()
df['Survived'].unique()
df['Sex'].unique()
array([3, 1, 2], dtype=int64)
array([0, 1], dtype=int64)
array(['male', 'female'], dtype=object)
unique()関数は、データに存在するユニークな値を返してくれるので、非常に便利です!
4. ユニークな数を視覚化する。
はい、データに存在するユニークな値を可視化することができます。そのために、私たちはseabornライブラリを使用します。sns.countplot()関数を呼び出し、カウントプロットをプロットする変数を指定する必要があります。
#Plot the unique values
sns.countplot(df['Pclass']).unique()
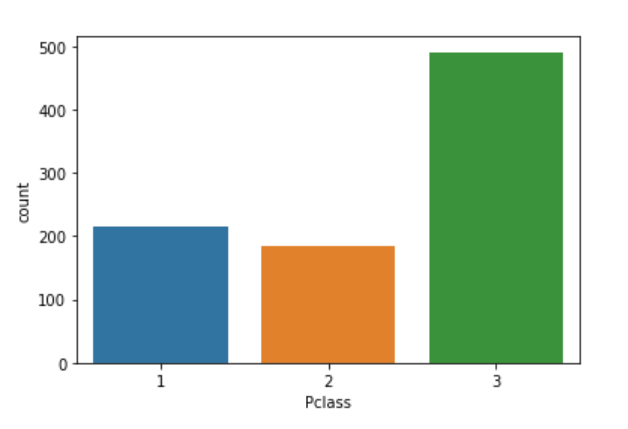
それは素晴らしいですね!あなたは上手くやっています。それはそんなに難しくないですよ。EDAには2つのアプローチがありますが、グラフィカルと非グラフィカルを組み合わせれば全体的な大局が見えてきます。
5. ヌル値を見つける
欠損値の発見は、EDAにおける最も重要なステップです。何度も言ったように、データの品質保証が最も重要です。では、どのようにして欠損値を見つけることができるか見てみましょう。
#Find null values
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
あらあら、『年齢』と『客室』の変数にヌル値がありますね。でも心配しないでください。すぐにそれらを処理する方法を見つけますよ。
6. Null値を置換する。
ねえ、null値を特定のデータで置き換えるためのreplace()関数があるよ。めちゃくちゃ便利だよね!
#Replace null values
df.replace(np.nan,'0',inplace = True)
#Check the changes now
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
わー!すごいですね。データ内のnull値を見つけて置き換えるのはとても簡単です。私はnull値を0で置き換えましたが、平均値や中央値など、より意味のある方法も選ぶことができます。
7. データ型を知っている
あなたが探索しているデータ型を知っていることは非常に重要であり、また容易なプロセスでもあります。それがどのように機能するか、見てみましょう。
#Datatypes
df.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age object
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
それで終わりです。このようにdtypes関数を使う必要があります。そうすれば、各属性のデータ型が得られます。
8. データをフィルターする。
はい、いくつかのロジックに基づいてデータをフィルタリングすることができます。
#Filter data
df[df['Pclass']==1].head()

上記のコードでは、クラス1に所属しているデータ値のみが返されていることが分かります。
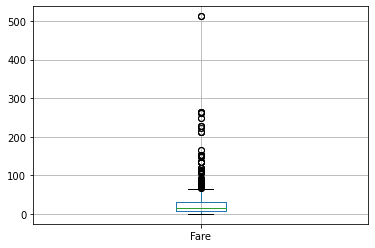
9. 短時間で作成された箱ひげ図
数値の列を使って、たった一行のコードで箱ひげ図を作成することができます。
#Boxplot
df[['Fare']].boxplot()
10. 相関プロット – 探索的データ分析
最後に、変数間の相関を見つけるために相関関数を利用することができます。これにより、異なる変数間の相関の強さについて公平なアイデアを得ることができます。
#Correlation
df.corr()
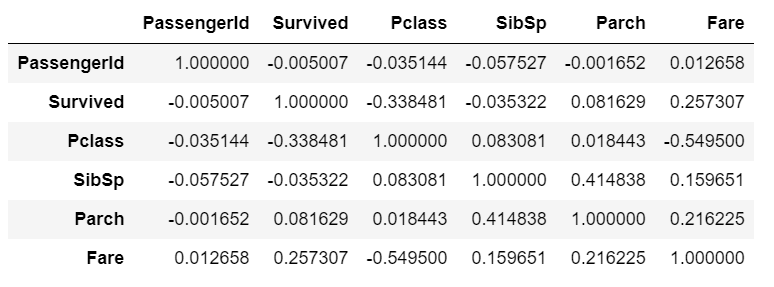
これは相関行列です。+1から-1までの範囲で、+1は高く正の相関があり、-1は高く負の相関があります。
以下のように、seabornライブラリを使って相関行列を視覚化することもできます。
#Correlation plot
sns.heatmap(df.corr())

エンディングノート-EDA
データの探索的分析(EDA)は、どんな分析においても最も重要な部分です。データについて多くの情報が得られますし、ほとんどの質問の答えがEDAによって見つかります。この記事では、Pythonを用いたデータの探索に使われる関数の多くを紹介しました。この記事から何かを得ることができれば幸いです。
今は以上です!Pythonを楽しんでください 🙂
もっと読む:探索的データ分析

